
...making Linux just a little more fun!
The Mailbag
By Kat Tanaka Okopnik
UPDATES from previous HELP WANTED: Article
Ideas
Submit comments about articles, or articles themselves (after reading our guidelines) to The Editors of Linux Gazette, and technical answers and tips about Linux to The Answer Gang.
 Running
Apache and AOLServer Together
Running
Apache and AOLServer Together
[Original question published as LG
122] help wanted #1]
[Evan] -
Modern AOL software for Microsoft Windows uses standard
protocols (PPP, PPPoE) to establish link-layer connectivity. It then establishes
a TCPIP connection to authenticate the user. This protocol is proprietary. Before
authentication, a user's network traffic cannot reach the internet.
To use AOL's ISP service on Linux, one must reverse engineer the authentication
protocol. I am not certain anyone has done that.
[Francis] -
Hi there,
If I understand things correctly, the intention is that
client --> s1.example.com:80 --> received by apache --> content
generated by apache --> content returned to client by apache
client --> s2.example.com:80 --> received by apache --> apache becomes
a client to s3.example.com:8080, which generates and returns content to apache
--> content returned to client by apache
I'm assuming above that the client should never know about or connect directly
to s3.example.com:8080 -- if that isn't the case, it becomes much easier.
Apache can do this.
In this case, s3.example.com happens to be the same as s2.example.com, but
that's unimportant.
In order for it to work, apache needs to know when it should serve something
itself, and when it should act as a proxy server for s3. To be a proxy, you'll
want mod_proxy and mod_proxy_http. The mod_proxy "ProxyPass" directive,
or the mod_rewrite RewriteRule [P] flag will be needed.
Another thing likely to be needed is for the content produced by the origin
server to be modified to be sensible from the eventual client's perspective
-- things like links, locations (e.g. for redirects), and cookies are the
main candidates. The best plan is to make sure the origin server knows how
it is being proxied, and to configure it to produce content appropriate for
the "real" client, rather than for the apache client it talks to
directly.
If that isn't done, you'll need extra features on the apache side to try
to catch any place the original details might leak. The "ProxyPassReverse"
directive is the first step; it can modify Location, Content-Location, or
URI headers from the origin server. You may also need "ProxyPassReverseCookieDomain"
and/or "ProxyPassReverseCookiePath" if the cookie-generating part
of the origin server wasn't configured as desired. You may also also need
something like the third-party mod_proxy_html to rewrite links (src and href
attributes) in the returned html, which may also require other modules or
libraries to do it right.
Some or fewer of those directives may not be available, depending on the
version of apache being used. That appears to be a secret.
Really, if you control the origin server, and will only be accessing it through
the front proxy, configure it so that everything it generates is as if it
were the world-facing server. With that, none of the content-transforming
directives will be needed.
The most general and, I would claim, easiest way to configure this is by name-based
virtual hosting.
(I know the OP said virtual hosting wasn't an option in this case, but I'll
try to be complete for the rest of the world.)
Logging and directories and the like which are set in the main config are
inherited by the virtual hosts, unless overridden there.
The first virtual host is the default one, used when the client-supplied
Host: header doesn't match any ServerName or ServerAlias in any VirtualHost
sections. Either make it a "please pick a configured site or use a better
client" area, or more likely, make it the main one. It's sensible to
set ServerName at least
NameVirtualHost [ip]
<VirtualHost [ip]>
ServerName s1.example.com
</VirtualHost>
<VirtualHost [ip]>
ServerName s2.example.com
# url hierarchy on this server --> remote server
ProxyPass / http://s3.example.com:8080/
</VirtualHost>
But since VirtualHost'ing is out, we need some other way of determining
which urls should be proxied and which should be handled directly.
The next most sensible way is to re-implement the relevant bits of virtual
hosting using mod_rewrite, conditional on the Host header sent by the client.
RewriteEngine on
RewriteCond %{HTTP_HOST} ^s2\.example\.com$ [NC]
RewriteRule /(.*) http://s3.example.com:8080/$1 [P]
The other ways I can think of are all quite silly, and involve "RewriteCond
%{HTTP_HOST}" or its moral equivalent in a server-side script to correctly
handle http://s2.example.com/ anyway, so I won't go in to them.
What else might matter...the content transforming, obviously, if you don't
configure the origin server to make it unnecessary. Oh, and all of the clients
the origin server sees will be from the apache server's address -- quite possibly
localhost, in this setup. So that server may want to play logging or other
games to produce pretty output. to produce pretty output.
tput
cwin question
[Mike's question was originally published in Mailbag
LG 123.]
Fri Feb 10 13:13:35 2006
Mike Wright (mike.wright
from mail.com)
Hi, I have been trying to figure out exactly what the "cwin"
option to the tput command really means.
[Ben] - According to 'man 5 terminfo', it defines a window. According to
real-life experience with a variety of xterms, it doesn't do much.
I find that this is generally the case with anything other than a few commands
that most xterms have in common. This isn't an area of *nix that has seen
much development lately (i.e., the last decade or more) because TclTk and
the like have made that kind of text layout, etc., a lot easier _and_ less
terminal-dependent than the kind of thing you're trying to do.
What I'm hoping that it will let me do is to create another window
in the current terminal using a section of the screen to output listings from
different commands that will be executed from numbered menu options. And if
the output is several screens then it can be presented a few lines at a time
to the user with the option to page down through the many screens of output
while not disturbing the menu options at the top of the screen nor the status
bars at the bottom of the screen.
I think that you're asking far more of xterms than they can provide. It
would be nice if it worked that way, but - as far as I'm aware - it does not.
Why not use several xterms (without decorations) arranged next to each other?
I use two tiny xterm windows with a very small font to show my connection
status and my mail status in the lower right corner of my screen, something
like this:
xterm -geometry 40x10-0-0 -name ppp -fn 6x9 -e pppd call cell-hs &
xterm -geometry 40x2-0-100 -name MailTail -e [long command line] &
I also have the above xterm names defined in my ~/.icewm/winoptions file
(however, unless you're using "icewm" as I do, these should probably
go in your ~/.Xresources file):
MailTail.dTitleBar: 0
MailTail.dClose: 0
MailTail.dMinimize: 0
MailTail.dMaximize: 0
MailTail.ignoreTaskBar: 1
MailTail.ignoreWinList: 1
MailTail.ignoreQuickSwitch: 1
ppp.dTitleBar: 0
ppp.dClose: 0
ppp.dMinimize: 0
ppp.dMaximize: 0
ppp.ignoreTaskBar: 1
ppp.ignoreWinList: 1
ppp.ignoreQuickSwitch: 1
Obviously, you can stack these however you want to. I find that this is
a lot more system-independent than trying to play around with terminfo capabilities.
GENERAL MAIL
Bind Error
Fri Feb 3 03:44:51 PST 2006
Roberto (roberto.bacenetti at lombardiacom.it)
I get an "Address already in use" when trying a bind in the
following situation:
a board with an ethernet and a ppp connection:
when the board starts only the ethernet interface is on, and
the program successfully binds to the specified port, and is able to accept
connections; at some point the partner disconnects and a GPRS PPP connection
is established, the old bind is already there and the program can accept a connection,
when however the connection is closed any bind will fail, even after a long
time has elapsed.
[[[Neil]]] - Reading this again, it sounds as though you are trying to bind
to the same port, while the original program is running. If you have bound
a socket it will stay bound, even if it has accepted a connection, which has
subsequently closed.
I haven't got my reference books handy, but IIRC, you bind() and listen()
on one socket, then accept() creates a second socket. The far end disconnecting
closes the second socket. If you want to bind to the the original port again,
you have to close the first socket also.
i wrote a test program which binds a socket to a specific interface
and port:
well with PPP on bind always fails.
[[[Neil]]] - Is PPP relevant here? Do you get the same failure with only
the ethernet connection?
Can somone explain this ?
[Neil] - Do answers 2.7and 4.5 in the Unix Socket FAQ answer your question?
http://www.faqs.org/faqs/unix-faq/socket/
[[Roberto]] - It' not a matter of time delay, the error is persistent and
I'm using SO_REUSE_ADDR
[[[[Neil]]] - netstat -tulp should tell you which program is already listening
on that socket.
thanks
Roberto
Webcams
Sun Feb 5 06:16:43 PST 2006
Mike Orr (sluggoster at gmail.com)
What was that program to view webcams on Linux? My friend in the UK
(the one mentioned in the iRiver thread) wants to videoconference. He's been
bugging me to get a webcam for months but I kept telling him it's such a pain
on Linux. Of course he doesn't understand this. "Just plug the camera in
and put the CD in the drive, and it installs itself." Yes, on Windows.
I found a webcam HOWTO on linux.com http://www.linux.com/howtos/Webcam-HOWTO/index.shtml
and it says some hundred models are supported, but it looks like installing
the hardware is only the first part of the problem. Everyone I know who uses
webcams transmits them through Yahoo Messenger. There's no like "Internet
camera protocol" so you can just attach the camera to a daemon listening
on a socket, and view somebody else's camera the same way? The HOWTO mentions
camE and Xawtv ('webcam' component), which uploads frames to a website. That's
the Linux way to project your webcam to the world? But it seems like it's only
good for getting the latest still on a webpage, not for watching a movie. And
how do you integrate sound with this?
[Vinayak] - Ayttm has had Webcam support for quite a while now AFAIK. I think
the other IM such as everybuddy which use libyahoo2 have webcam support as well.
[Jimmy] - GnomeMeeting (http://www.gnomemeeting.org/)
is probably the best known video conferencing app for Linux. There's also a
fork of Gaim that has voice and video support (http://gaim-vv.sourceforge.net/).
drvspace under LINUX
Thu Feb 9 14:17:15 PST 2006
Jim Doutt (jdoutt-at-whoi-dot-edu)
I am backing up an old DOS disk. It had several 'pseudo' drives (K:,
L:) implemented under 'drvspace', which created a file for each drive and treated
the contents of the file as a disk.
Using an ISA to USB adapter, I plugged the drive into my Fedora core
3 system and created a image of the whole partition .
dd if=/def/sda1 of=bkup.img
I then did a loopback mount of that image file 'bkup.img'.
mount -o loop=/dev/loop3 TI_Travelmate_sda1_windows_20060206.img zz
Great...I can see the DOS files in that image. I also see the files
drvspace.000, and drvspace.001 which correspond to my K: and L: drives.
I would like to see the files inside these drvspace files. I have read
over dmsdos, but as far as I can tell it was never ported to the 2.6 kernel.
I did find a reference to doing a loopback mount using ',cvf_type' mount -o
loop=/dev/loop2,cvf_type=dblspace dblspace.001 ../q2 I tried this, and no errors
were reported with the mount. However the files and directories had funny names
(e.g. ?????.??? etc. ) so the mount was not done properly
Is there a way to do this under LINUX?
[Rick] - I think your only direct access under Linux to those files will be
to use the real Microsoft drvspace.bin driver under the "dosemu" emulator.
This apparently works well enough, and is detailed here:
http://trillian.randomstuff.org.uk/~stephen/linux/msfilesys.shtml
Over the longer term, you are strongly advised to extract those files from
compressed storage, if you care about them. Not only is DriveSpace (and DoubleSpace)
pretty unreliable -- and antique -- but also it's just way too darned much
trouble to deal with this stuff on an ongoing basis, in my opinion. Good luck!
SMS sending S/W
Tue Feb 28 03:57:15 PST 2006
J. Bakshi (j.bakshi at 1net.gr)
Hi list,
there are some sites which can send SMS to mobile. Generally these
sites send SMS based on online operation. there are some microsoft based S/W
(limited period trial version) too which allow you to compose your messages
offline and then send it after connecting with the net; just like SMTP :-) [though
I have not tried anything as my box is debian] BUT is there any such Linux based
tool allowing offline SMS composing and sending all after getting net connection
??
[Thomas] -
[n6tadam at workstation ~]$ apt-cache search --names-only sms
sms-pl - Send SMs via Polish GSM operators
smsclient - A program for sending short messages (SM / SMS)
smssend - Utility to send SMS messages to GSM mobile phones
smstools - SMS Server Tools for GSM modems
[[jbakshi]] - Thanks a lot Thomas.
[Jimmy] - You've been asking questions here for a while, so this won't come as a surprise:
you need to provide more information :)
Short answer: yes, there is software for Linux that will allow you to compose
and send SMS messages:
http://tuxmobil.org/phones_linux_sms.html
Long answer: In fact, there are three main ways of doing this: via a web
interface, mobile phone, and any GSM capable modem. (There are other ways;
ICQ for Windows, for example, once had a way of sending SMS via ICQ, but AFAICT
that has been discontinued). Heck, you can even run your own SMS (and WAP)
gateway on Linux: http://www.kannel.org/
or http://smscgw.ccamp.de/
Web interfaces: I mentioned that you needed to provide more information -
which website do you want to use, or, failing that, which network(s) do you
want to send to? These programs are basically screen scrapers, and need to
be aware of the layout of the site you want to use. smssend http://zekiller.skytech.org/smssend_menu.html),
for example, can use several operator's websites, as can the Perl module WWW::SMS
(http://search.cpan.org/~eim/WWW-SMS/)
- they may not be configured for the network you want to use, however. SMTP2SMS
seems
to be configured for Indian providers, so maybe that's what you want? https://sourceforge.net/projects/smtp2sms/
If you want to send messages using your mobile:
- Gnokii: http://www.gnokii.org/ (supports Nokia specific features, though
most basic features can be used with any GSM-capable mobile)
- Gammu: http://www.gammu.net/ (Fork of Gnokii, supports some things Gnokii
doesn't)
- KMobileTools: http://kmobiletools.berlios.de/
- Gnome Phone Manager: http://usefulinc.com/software/phonemgr/
Using a GSM modem: I can't find the software I used to use, but GSMlib (http://www.pxh.de/fs/gsmlib/)
provided the functionality it used.
KXicq2 (http://www.kxicq.org/), an ICQ client for KDE, has support for sending
SMS - I'm pretty sure Kopete and Gaim have plugins to do the same. There's
even a project that allows a mobile to be mounted as a file system (http://www.gammu.net/projects/snofs.php)
that is planning support for sending SMS this way.
HTH
2 CENT TIPS
A 2 Cent Tip for Using an Iriver IFP-890 MP3 Player on Linux
Sat Feb 4 19:40:47 PST 2006
Chris Gianakopoulos (cgianakop
at 1stconnect.com)
Hi Gang,
Here is my latest 2 cent tip for the year (I hope I have more coming).
I've been stuggling on how to get my iRiver mp3 player to interpoerate
with my Linux system. The purpose of this posting is to share my results. I
have an IFP-800 series player, and it has been updated with firmware so that
it appears as a USB storage type of device. Specifically my model is an IFP-890
player.
My Linux distribution is SuSE 8.2, and here are the steps that I performed.
0. Make sure that USB is enabled for hotplug stuff on your system.
1. Update your iRiver mp3 player with their UMS software. The website
is here.
You should see a link titled,
iFP-890(cn)_V185ums.zip (1.4 MBytes)
Go ahead and download this file, and reflash the player using the software
provided with your mp3 player.
2. As root, create two files to be stored in /etc/hotplug/usb. The
two files are called ifpdev and ifp.usermap. The first file will be executed
when you plug your mp3 player into your USB port, and the second file describes
the required parameters such as vendor id and model. The two files appear below.
** Begin ifpdev **************************************
#!/bin/sh
# /etc/hotplug/usb/ifpdev
chgrp usb $DEVICE
chmod g+rw $DEVICE
End ifpdev ****************************************
** Begin ifp.usermap *********************************
ifpdev 0x0003 0x4102 0x1108 0x0000 0x0000 0x00 0x00 0x00 0x00 0x00 0x00 0x00000000
** End ifp.usermap **********************************
3. As root, add an entry in /etc/fstab. The entry appears below.
** Begin fstab entry *********************************
/dev/sda /media/usbDrive auto rw,noauto,user,exec
** End fstab entry **********************************
4. As root, create a directory:
mkdir /media/usbDrive
Now that you've performed all the setup stuff, you just plug your mp3
player into your USB port, and you should hear some beeps indicating recognition
of a device being plugged in. Type 'mount /media/usbDrive'.
Now you could access all your music (and whatever else) files :) .
Enjoy!
Chris G.
I forgot to mention in my previous post the source of the script for the
hotplug thing. It is http://www.roback.cc/projects/iRiver/.
When I got my mp3 player it didn't have USB filesystem support. I found out
about it in a yahoo linux chatroom. Then I beat my head against a wall for
about a month after that spending some spare time getting it to interoperate
with a linux system. It did pay off. :)
Chris G.
Simple 2-pence tip: Vim
:paste / :nopaste
Wed Feb 8 13:50:39 PST 2006
Thomas Adam (
thomas
at edulinux.homeunix.org)
This one is so simple, it's probably always overlooked by many --
or some other alternative solutions are used. There are times (such as viewing
a webpage), when one performs "cut-and-paste" from that page, into
an editor. I use Vim running in an rxvt. Sometimes (depending on the CR at the
ends of the line, there'll be a "stair-case" effect. In the past,
I would do (in normal mode):
ggVG=
to reformat (and reindent) the text, but even that's not always the
full solution. The "preferred" way is to do this:
:set paste
before you paste the text into vim. Then when you're done, issue:
:set nopaste
... and carry on as normal. It's great. :)
[Kapil] -
I did have this problem (though not with "vim" but "elvis"
since that's what I use) and recently found that
:set noai
before the paste and
:set ai
after the paste seems to do the trick. (For non-vi types to get a clue "ai"="autoindent").
"elvis"/"nvi" don't seem to know the "paste" variable/option.
[Ben] -
I just use ":a", then paste and hit 'Esc'. Works for me.
2Cent
Tip: Comparing all files in a directory
Fri Feb 24 10:26:34 PST 2006
Suramya Tomar (
suramya at suramya.com)
Hi Everyone,
Recently I had to compare all files in a directory with all files in another
directory to see which of the files had changed and what the differences were.
To run a diff on each file would have taken forever (there were over
300 files in the directory) so I wrote the following script to compare all the
files in the current directory with its counterpart in the target directory:
#!/bin/sh
# compare_entire_dir.sh
# Lets you compare all the files in the current directory with the
# files in the specified directory.
#
# Suramya Tomar (suramya at suramya.com)
# 23rd Feb 2006
#
# Syntax: ./compare_entire_dir.sh target_directory
##############################################################################
for file in *;
do
echo "Comparing: $file" >> ../compare_results.dat;
diff -ibw "$file" $1/$file >> ../compare_results.dat ;
done
It worked surprisingly well for me so I thought I should share it with
you all. Hope you find it useful.
Thanks,
Suramya
[Thomas] - I just use 'dirdiff', personally.
[[Peter]] Oooh, nice one, thanks! :)
I wonder if the "unison-gtk" folks ever talked to the "dirdiff"
folks...
In unison, it'd be nice to be able to take a quick look-see sometimes, to
figure out what actually changed in the files (the way dirdiff shows when
you double-click on it).
unison works nicely across ssh, that's why I tend to use it a lot for syncing
directory trees (at the time, it seemed easier to pick up and understand than
rsync).
[Faber] - I just use 'diff', personally.
[Ben] - I just hit 'Ctl-x d' in Midnight Commander. But Faber's method is definitely
more portable.
[[Suramya]] - Umm.. I did use diff to make the actual comparison, the script
just loops through each file in the current directory and runs a diff of it
against the same file name in the target directory.
[[[Ben]]] - Sure, that was very clear from your script. However, 'diff' is
one of those utilities that can take either files _or_ directories as arguments.
Here's an example of how it works:
ben at Fenrir:~$ mkdir /tmp/foo /tmp/bar
ben at Fenrir:~$ for n in {a..z}.txt; do cp /etc/hosts /tmp/foo/$n; done
ben at Fenrir:~$ cp /tmp/foo/{b..y}.txt /tmp/bar
ben at Fenrir:~$ echo >> /tmp/bar/y.txt
ben at Fenrir:~$ echo >> /tmp/foo/b.txt
So, I've just created a 'foo' and a 'bar' directory in '/tmp', created a
list of files in 'foo' (all copies of my '/etc/hosts'), copied the list (except
for two files) to 'bar', and slightly modified one file in each directory.
Ready? Here we go:
ben at Fenrir:~$ diff /tmp/foo /tmp/bar
Only in /tmp/foo: a.txt
diff /tmp/foo/b.txt /tmp/bar/b.txt
34d33
<
diff /tmp/foo/y.txt /tmp/bar/y.txt
33a34
>
Only in /tmp/foo: z.txt
ben at Fenrir:~$
'diff' shows the results of all the differences - both in the list of files
and in the files themselves. Pretty good little prog, hey? :)
[[[[Martin]]]] - Didn't know diff could do dirs as well as files... You learn
summat new every day... ;)
[[[[Karl-Heinz]]]] - It even has a "-r" flag for recursive diff down
the dir-tree (or would that be up as for real trees?)
[[[[Suramya]]]] - ahh.. didn't know that... Thanks for the info.
This also proves the theory that the more you share/teach the more you learn
'cause if I hadn't shared my script I wouldn't have found out that diff supports
directories. :)
Thanks,
Suramya
[[[[[Ben]]]]] - I couldn't agree more. I always tell my students to ask lots
of questions, even if they seem silly. Discovering the misconceptions they have
is just as important as the understanding they're getting from being in class,
and perhaps even a bit more than that; once they have the correct perspective,
then even their wild guesses are likely to be right.
GAZETTE MATTERS
Woomert Foonly
Tue Feb 28 2006 10:33:29 -0800
Bradley Chapman (
kakadu
from gmail.com)
What happened to Mr. Okopnik's Perl guru Woomert Foonly? I was reading
back issues of LG and was quite impressed with the stories showcasing the interesting
data-munging features offered by Perl, as well as the amusing storylines; are
any new stories going to be written?
[Ben] Um... well... good question, Brad. I've been waiting for inspiration
to strike, but I seem to be having a long dry spell, inspiration-wise. In
fact, I started a story about Woomert and Frink a while back, ran into a major
plot snag (what kind of a problem can aliens from another universe have that
can be solved with Perl???), and... well, there it's sat, ever since. I've
tried writing some other W&F stories a couple of times, but got nowhere.
However, the occasional reminders are useful and stimulating. If another
Woomert story comes out in the near future, it'll be your fault. :)
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/tanaka-okopnik.jpg)
Kat likes to tell people she's one of the
youngest people to have learned to program using
punchcards on a mainframe (back in '83); but the
truth is that since then, despite many hours in
front of various computer screens, she's a
computer user rather than a computer programmer.
When away from the keyboard, her hands have been
found full of knitting needles, various pens,
henna, upholsterer's shears, and a pneumatic
scaler.
Copyright © 2006, Kat Tanaka Okopnik. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
News Bytes
By Howard Dyckoff
 |
Contents:
|
Please submit your News Bytes items in
plain text; other formats may be rejected without reading.
[You have been warned!] A one- or two-paragraph summary plus a URL has a
much higher chance of being published than an entire press release. Submit
items to bytes@linuxgazette.net.
News in General
 Will Oracle buy a Linux OS provider?
Will Oracle buy a Linux OS provider?
"I don't see how we could possibly buy Red Hat... I'm not going to spend $5
billion, or $6 billion, for something that can just be so completely wiped off
the map," Ellison was quoted as saying in the FT. He also said that he had
considered making an offer on Novell.
Ellison did mention supporting or buying a small distro and building it up
for the Oracle user community. Ubuntu and Mandriva are possibilities cited by
commentators.
"At some point we could very well choose to have Linux as part of the Oracle
database server. We certify it, we test it. We could have JBoss as part of our
middleware. It costs us nothing. We can do that, IBM can do that, HP can do that
- anyone with a large support organization is free to take that intellectual
property and embed it in their own products."
And: "Why didn't we buy JBoss? Because we don't have to. If it ever got good
enough we'd just take the intellectual property - just like Apache - embed it in
our fusion middleware suite, and we're done."
The full Financial Times story is here:
http://news.ft.com/cms/s/5f7bdc18-ce85-11da-a032-0000779e2340.html
Will Sun Open Source Java?
The rumor mills are reporting internal debate at Sun over how far to go with
its ongoing Open Source initiative, up to and including fully Open Sourcing Java.
This is all motivated by need to make some statement of direction for the
upcoming JavaOne conference in May.
With Sun Microsystems CEO Jonathan Schwartz newly settled in after the
departure of Scott McNealy, the pressure to go the OSSw way is mounting. But the
real issue is helping Sun's bottom line.
Sun has historically tried to prevent forking within the Java source tree to
maintain its 'run everywhere' goal. On the other hand, Microsoft's C# borrows
heavily from Java and is a major alternative. Also the work on Eclipse plugins
and IDEs for scripting languages like PHP may be undercutting the position of
Java in the developer community.
Introducing MySQL Forge
MySQL AB has introduced MySQL Forge, a new Web site and community directory
designed to support active MySQL-related open source development. Located at
http://forge.mysql.com, MySQL Forge is a central online resource for all MySQL
users and developers to communicate, collaborate and share MySQL code and
applications.
MySQL now also supports Ubuntu, a popular version of Linux. In a keynote
address at the 2006 MySQL Users Conference, Mark Shuttleworth, founder of the
Ubuntu project, outlined the new partnership. Shuttleworth said, "The new
partnership and technology support between MySQL and Ubuntu will make it much
easier for our joint communities and customers to build and use everything from
Web 2.0 applications to large, business-critical software, on the Ubuntu-MySQL
platform."
Linux Desktop goes to LSB 3.1
At the recent Linux Desktop Summit in San Diego, the Free Standards Group
announced support of the current Linux Standard Base (LSB) 3.1 standard for
desktop applications by 14 Linux vendors. This is the first version of the LSB
to include portable Linux desktop applications. The initial group, which is sure
to grow, included Ubuntu, Xandros, Red Hat and Novell and system vendors Dell,
HP and IBM.
LSB 3.1 also incorporates the recently approved ISO standard LSB Core
(ISO/IEC 23360) into the standard.
Greater participation of Linux distribution vendors and upstream maintainers in
the LSB development process will make it easier to synchronize roadmaps and improve
binary compatibility. This initiative will be kicked off at the FSG Summit
on June 1 and 2, 2006 in Boston with participants from major
distributions, upstream maintainers and ISVs.
"LSB 3.1 is a big step forward for the Linux desktop. freedesktop.org is
looking forward to working closely together with the Linux Standard Base to
drive even more desktop related technology into the next revision of LSB," said
Waldo Bastian, a senior software architect at freedesktop.org.
"LSB-compliance is very important for Ubuntu," said Mark Shuttleworth, Ubuntu
founder and chief developer. "We believe that Linux offers the world freedom of
choice, freedom to innovate and freedom to localize. The Linux Standard Base is
a crucial enabler of those freedoms, creating confidence in the standardization
of the core platform while still preserving the ability of the platform to
evolve and improve."
SuSE flaws in KDE
Several flaws and vulnerabilities in the desktop KDE environment have been
discovered and patched in the latest release of SuSE. These could exploited by
attackers to access sensitive information or run arbitrary code on an affected
machine.
READ MORE at http://www.networkworld.com/weblogs/alerts/2005/008545.html
and http://www.novell.com/linux/security/advisories/2005_22_kdelibs3.html
Novell buys security monitoring firm e-Security
Novell has bought e-Security, a security information management and
compliance monitoring firm, in a deal worth $72 million. e-Security's key
product is Sentinel 5, a total-enterprise view of attacks and policy violations.
Novell said this software provides "...Automated Compliance Monitoring and
Reporting."
Novell estimates a positive revenue impact from the acquisition of roughly
$20 million in the coming 12 months. Their webcast on the acquisition is
available here.
Read more at http://www.novell.com/news/press/item.jsp?id=579
Conferences and Events
-
==> All LinuxWorld Expos <
==
- http://www.linuxworldexpo.com/live/12/media/SN787380
- SecuritySolutions 2006
- May 1-4, Tampa, FL
- SecureWorld Expo
- May 2-3 2006, Atlanta, GA
- CardTech/SecurTech 2006
- May 2-4, Moscone Center, San Francisco, CA
- JavaOne Conference
- May 16-19 2006, Moscone Center, San Francisco, CA
- Red Hat Summit
- May 30 - June 2 2006, Nashville, TN
- SOA Web Services Edge Conference & Expo and
Enterprise Open Source Conference [co-located]
- 5-6 June, New York, New York
- 21st Int'l Supercomputer Conference
- June 27 - 30 2006,Dresden, Germany
- O'Reilly Open Source Convention 2006
- July 24-28, Portland, OR
- LinuxWorld Conference & Expo -- SF
- August 14-17, 2006 -- in foggy San Francisco, dress warmly!!
- YAPC::NA
- June 26-28 2006, Chicago, IL
http://use.perl.org
- Dr. Dobb's Architecture & Design World 2006
- July 17-20, Hyatt Regency McCormick Place Conference Center, Chicago, IL
- YAPC::EU
- August -- 01 September, Birmingham, U.K
- SD Best Practices 2006
- September 11-14, Hynes Convention Center, Boston, MA
- GridWorld 2006
- September 11-14, Convention Center, Washington, DC.
- Rules Technology Summit
- November 5-9, 2006, Omni Shoreham Hotel, Washington, DC
- http://rulestechnologysummit.com/index.php
FREE Commercial Events of Interest
Sun MicroSystems will host a free NetBeans Software Day
concurrently with the 2006 JavaOne Conference tutorial day. James Gosling and
other Java luminaries will present at this pre-JavaOne event. Register now for
your chance at free books, USB RAM giveaways, and more. Attend Monday, May 15,
2006 at the Argent Hotel in San Francisco. Details: http://enews.sun.com/CTServlet?id=106665198-988673072:1146175386207
In addition, Sun has just added a free bonus evening
course, "Exploring Ajax & JavaServer Faces (JSF)". This evening course is
only available to those attending one of the four Java University tutorial
courses held during the day on May 15. Details are here : http://enews.sun.com/CTServlet?id=106665198-988673072:1146175386215
Distro news
The latest stable version of the Linux kernel is:
2.6.16.11 [ http://www.kernel.org/pub/linux/kernel/v2.6/patch-2.6.16.11.bz2
]
The latest test version Linux kernel tree is:
2.6.17-rc3-git3 [ http://www.kernel.org/pub/linux/kernel/v2.6/testing/patch-2.6.17-rc3.bz2
]
SUSE Linux 10.1 Beta
SUSE Linux 10.1, code name 'Agama Lizard' RC3, is
availabile with fixes for the majority of bugs from RC2. Please read the Most
Annoying Bugs for RC3 here before you decide to download it. [ http://en.opensuse.org/Bugs:Most_Annoying_Bugs#SUSE_Linux_10.1_RC3
]
Debian AMD64 port
Debian GNU/Linux: the project's Debian AMD64 port is now officially included
in the Debian unstable branch and will soon be added to the testing tree. As a
result, users of the unstable and testing branches of the increasingly popular
64-bit platform should update their sources list file to point to the new tree,
rather than to amd64.debian.net, which will no longer be updated. Users of the
stable Debian AMD64 port can continue to use the original FTP server and can
obtain security patches from security.debian.org.
CentOS 3.7
CentOS 3.7 has been released: "The CentOS development team is pleased to
announce the availability of CentOS 3.7. Major changes in this version of CentOS
include: Added Intelligent Platform Management Interface (IPMI) functionality to
CentOS-3. IPMI is a standard for controlling intelligent devices that monitor a
system. It provides for dynamic discovery of sensors in the system and the
ability to monitor the sensors and be informed when the sensor's values change
or go outside certain boundaries. To use IPMI, you need an interface to an IPMI
controller in your system (called a Baseboard Management Controller, or BMC) and
the IPMI software."
SimplyMEPIS 6.0 Beta
The first beta of the new Ubuntu-based SimplyMEPIS 6.0 has been released for
public download and testing: The KControl system configuration shell has been
replaced with the SystemSettings shell from the Ubuntu Project. This was in
response to suggestions from the MEPIS user community. Also reliability has been
enhanced by a delay on logout to prevent disk sync problems and an automatic
fsck on login. [BTW, "Ubuntu Linux" is now officially just "Ubuntu"]
Said MEPIS founder Warren Woodford, "We've released 2
alphas and we are ready to do a beta." Get SimplyMEPIS 6.0-beta1 here [http://ftp.wustl.edu/pub/linux/distributions/mepis/
] The final release is
scheduled for around June 1, 2006. Beta2 is planned for approximately May 3.
Software and Product News
HP Simplifies Management for Linux on Blades
HP's new Control Tower software simplifies the management of Linux on blade
servers with technology gained through HP's acquisition of RLX last year. In
addition, HP Control Tower can work in conjunction with HP Systems Insight
Manager to provide simplified lifecycle management of blade servers running
Linux by using familiar open-source tools.
The management features of HP Control Tower are :
- -- Simple set-up -- Less than 30 minutes required to
install and configure the management server
- -- Management -- Tightly integrated package delivers hardware monitoring and
deployment functions in one console. HP Control Tower uses a secure management
network to ensure reliable monitoring and simplified remote management for HP
BladeSystem
- -- Linux-friendly -- Intelligently packages
open-source tools familiar to Linux users
HP Control Tower is expected to be available in May for
$199 per license. More information on HP Control Tower is available at www.hp.com/go/controltower
.
SCO include mobility services
SCO has been seen on the conference circuit demonstrating two new mobility
services they call VOTE and SHOUT. With Shout you can send a 60-second custom
audio message to any number of people through a Web browser. Vote is an easy
polling service that lets you gather instant opinions and manage feedback in a
mobile environment. Both were demonstrated at recent conferences, including the
MySQL user conference, as part of its 'Me, Inc.' initiative. [I picked up a free
CD, but its trialware that times out in 60 days.] This also shows that they are
still developing software.
IBM and the X Factor
IBM has unveiled System X to replace its eServer X Series. The new x86 line
includes the System x3800, x3850 and x3950 servers, will have virtualization
switched on by default [previously it was off]. So the machines are 'virtually'
the same as its xSeries 260 and up models.
IBM polled its customer base and learned that the majority of them would
pursue data center virtualization projects with planned hardware projects. These
servers will work with VMWare and Xen hypervisors.
Magical Realism... (non-Linux news of general interest)
Virus threatens both Linux and Windows
Hackers have released proof-of-concept code for a virus that can infect both
Linux and Windows systems. The virus, which was given the symmetric name
'Virus.Linux.Bi.a/ Virus.Win32.Bi.a', was reported by security firm Kaspersky
Lab. While it does not carry a malicious payload, security researchers there
worry that this malware is part of a trend of viruses that can run on Windows
and other operating systems. In this case, code infects both PE (Portable
Executable) and ELF (Executable and Linking Format) file types.
Although this is worrying, it is not entirely without precedent. In 2001 the
"ELF/Winux.2784" virus was also able to infect both Linux and Windows
platforms.
Read more here : http://www.techweb.com/wire/184429692
and http://www.networkworld.com/nlvirusbug29990
[ Considering that writing to a Linux system
executable requires root privileges, the above "threat" has exactly zero
effect on the security profile of Linux. As always, the requirement for
damaging a Linux system continues to consist of "first, get root access..."
-- Ben ]
Beta test new AJAX-ified Yahoo! Mail
AT&T Inc. and Yahoo! beta test new AJAX-ified Yahoo! Mail
Highlights of the beta version of AT&T Yahoo! Mail include a faster
[AJAX-based] web interface and:
- -- Fast and easy-to-use interface that functions
like a desktop client application.
- -- Drag-and-drop message organization.
- -- Reading pane to view messages instantly.
- -- Ability to view multiple e-mails at the same time, using tabbed
navigation.
- -- Integrated RSS reader, providing access to breaking news, blog entries and
other feeds directly in the Web mail experience.
- -- Automatic check and delivery of new mail.
- -- Keyboard shortcuts and right-click menus.
- -- Ability to scroll through all message headers in a folder, rather than
page by page.
Samsung Develops 3D Memory Package
Samsung Electronics Co., Ltd., a leader in advanced memory technology, has
developed a small-footprint, wafer-level stack package (WSP) of high density
memory chips using 'through silicon via' (TSV) interconnection technology. WSP
reduces the physical size of a stacked set of semiconductor chips, while greatly
improving overall performance. The next generation in package technologies, WSP
can be applied to memory and processors to deliver higher speed and higher
density packaging.
Using this technology, mobile device and consumer electronics manufacturers
can make slimmer, high-performance handsets with longer battery time.
Samsung's industry-first WSP is a 16Gbit memory solution that stacks eight
2Gb NAND chips. The WSP generates a much smaller multi-chip package (MCP), which
is the current mainstream solution for designing miniaturized, high-capacity
memory devices. Samsung's eight-chip WSP prototype sample, which vertically
stacks eight 50-micrometer, 2Gb NAND flash dies, is 0.56 millimeters in
height.
Samsung's WSP technology reduces production cost by using a tiny laser to
drill the TSV holes. WSP also reduces the length of the interconnections,
resulting in an approximately 30-percent increase in performance from reduced
electrical resistance. This makes it attractive for applications requiring lower
power consumption, higher performance and higher density, such as today's
slimmer handset designs. Samsung will apply its WSP technology to mobile
applications and consumer electronics in early 2007.
Restraining Order Against the Geek Squad
The Feds granted a request by Winternals Software for a temporary restraining
order (TRO) requiring that Best Buy Co. and its Geek Squad subsidiary to stop
using unlicensed versions of Winternals' software.
The lawsuit alleges that Best Buy and Geek Squad used illegal copies of ERD
Commander 2005, a system repair and data recovery tool that boots a dead
computer into a Windows-like environment for rapid system recovery. The software
helps restore deleted data, reset passwords, copy files to and from unbootable
systems, edit the registry, and access Restore Points on a dead Windows
computer. The software is regarded as the most complete set of administrative
system tools available for the Windows professional.
In its lawsuit, Winternals claimed that Best Buy and Geek Squad contacted
Winternals in October 2005 about purchasing a license that would allow their
12,000 employees to use Winternals' software in their jobs. The licensing would
have covered most Geek Squad employees at a cost of several million dollars.
The lawsuit alleges that during the next three months, Winternals and the
defendants entered into a trial-and-test agreement. The complaint contends that,
in February 2006, the defendants abruptly informed Winternals that they were no
longer interested in pursuing a licensing agreement but still continued to use
Winternals' software.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/dyckoff.jpg) Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Copyright © 2006, Howard Dyckoff. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
Preventing DDoS attacks
By Blessen Cherian and Ben Okopnik
Note from the Editor
C is as sphere as Earth. It's center is everywhere and circumference is
nowhere and hence what you see in daylight is only one percent of what you
can see in darkness.
-- cited from an article submitted to LG (anonymous)
With the agreement of the original author of this article, I've listed
myself as co-author here, since I essentially rewrote the article that was
submitted. Normally, proofing an article and adding some HTML structure is
just part of the job here at LG; however, complete reformatting of idiom,
recasting of nearly every paragraph, and updating the technical information
is well beyond the scope of what is normal.
I hate to reject an article that has excellent technical merit almost as
much as I want to avoid publishing one that would be unintelligible to many
of our readers (particularly those for whom English is not their primary
language, or who have difficulty parsing it for other reasons.) However, I
also feel that doing what is essentially a major rewrite of an article
should not go unrecognized. Since this is the first time I've ever
explicitly taken credit for doing this kind of major reconstruction - and
since my own vewpoint here could be tainted by the fact that it's my work
that's involved - I want to solicit comments, ideas, and suggestions from
you, our readers. Anyone want to volunteer as a stand-by co-author? Got an
alien idiom-conversion ray that's been in your attic for the last hundred
years? Do you see some other obvious solution I've missed? Bring'em on; the
'Talkback' link at the end of this article is your friend.
-- Ben Okopnik, Editor-in-Chief
Introduction
In this article, I will try to explain what DDoS is, and how it can be
prevented or mitigated. Many of the servers in datacenters these days are
Linux-based; hence, I'm going to discuss DDoS attack prevention and
mitigation for Linux servers.
DDoS happens due to lack of security awareness, application, or skill on
the part of the network/server owners or adminstrators. We often hear that
a particular machine is under DDoS attack, or that the NOC has unplugged a
given machine due to its participation in a DDoS attack. DDoS has become
one of the common issues in our world. In some ways, DDoS is like a disease
which doesn't have a countering antibiotic, and requires being very careful
while dealing with it. Never take it lightly. In this article,
I'll try to cover the steps/measures which will help us defend our machines
from a DDoS attack - at least up to a certain extent.
What Is A DDoS Attack?
Simply stated, DDoS (Distributed Denial of Service) is an advanced version
of the DoS (Denial of Service) attack. Much like DoS, DDoS also tries to
block important services running on a server by flooding the destination
server with packets. The specialty of DDoS is that the attacks do not come
from a single network or host but from a number of different hosts or
networks which have been previously compromised.
DDoS, like many other attack schemes, can be considered to consist of three
participants; we can refer to these as the Master, the Slave, and the
Victim. The Master is the initial source of the attack - i.e., the
person/machine behind all this (sounds COOL, right?) The Slave is
the host or network which was previously compromised by the Master, and the
Victim is the target site/server under attack. The Master informs the
Slave(s) to launch an attack on the victim's site/machine; since the attack
comes from multiple sources at once (note that the Master is usually not
involved in this phase), it is called a Distributed (or
co-ordinated) attack.
How Do They Do It?
DDoS occurs in two phases. In the first phase, the owner of the Master host
compromises vulnerable machines in different networks around the world and
installs DDoS tools (i.e., programs that will perform the attack once
they're triggered.) This is called the Intrusion phase. In the next phase,
the Master sends out the triggering information to those compromised hosts,
which usually includes the IP to be attacked (conversely, that IP could
have been pre-programmed into the tools, and the attack could be
time-triggered - e.g., the Code Red virus DDoS against the
http://whitehouse.gov servers.) This is called the Attack phase.
What Allows Them To Do It?
The success of the Intrusion phase relies on the presence of vulnerable
machines on an arbitrary network. Unfortunately, there's a very large
number of naive computer owners and system administrators whose machines
are largely unprotected, and thus this phase will be easily accomplished by
the attacker in almost all cases.
Some of the factors that make the Slaves-to-be vulnerable are:
- Vulnerable software/applications running on a machine or network.
- Open/unprotected network configuration.
- Hosts configured without taking security into account.
- Absence of monitoring or data analysis.
- No regular audit or software upgrades being conducted.
What Should We Do If We Are Under Attack?
If your host is one of the Slaves in a DDoS, you will most likely never
even be aware of it - unless you carefully examine your logs and watch for
untoward network activity. If, on the other hand, you're the Victim, the
results will be dramatic and obvious.
Symptoms (Victim):
- Programs run very slowly
- Services (e.g., HTTP) fail at a high rate
- Large number of connection requests from different networks
- User complaints about slow (or no) site access
- Machine shows a high CPU load
If you discover that you're under attack, follow these steps:
- Check if your CPU load is high and you a have large number of
HTTP process running
Check the load using the 'w' or the 'uptime' commands:
Blessen@work >w
12:00:36 up 1 day, 20:27, 5 users, load average: 0.70, 0.70, 0.57
Count the number of HTTP processes (it helps to know what your normal
count is for comparison):
[root@blessen root]# ps -aux|grep -i HTTP|wc -l
23
- Determine the attacking network
In a heavily-loaded server, the number of connection may be above 100 - but
during a DDoS attack, the number will go even higher. That's when we need
to find out, as quickly as possible, which networks are launching these
attacks. In a DDoS attack, the individual slave machine doesn't have much
importance; it is the network which matters the most, since an attacker
could be using any or even all of the machines on a compromised network.
Consequently, the network address is of crucial importance.
Executing the following command will show the IPs arranged in order of
established connections:
bash# netstat -lpn|grep :80|awk '{print $5}'|sort
For an average host, if you have more than 30 connections from a single IP,
chances are that you're under attack. In normal operation, there is very
rarely any reason for that many connection requests from a single IP.
Identify these networks for later reporting, perhaps by using the 'whois'
command.
If more than 5 such hosts/IPs connect from the same network, that's a
very clear sign of DDoS.
- Block the attacking network
This can be done by using 'iptables' or 'apf':
iptables -A INPUT -s <Source IP> -j DROP
If you're running 'apf', simply add these IPs to the
'/etc/apf/deny_hosts.rules' file. Continue this elimination process until
the attack on the machine is reduced (and hopefully, eventually stopped
altogether.) As a follow-up measure, contact the datacenter/NOC responsible
for that network to inform them of the compromised systems.
As a longer-term strategy, once the immediate attack is over (or, if you're
smart, you can do it right now :), install Portsentry (see the software
listed at the end of this article.)
How can we prevent or defend ourselves from these attacks?
There is no complete or perfect solution to DDoS. The logic is simple: NO
software or countermeasures can stand up to attacks from, say, 100 servers
at once. All that can be done is to take preventive measures, and respond
quickly and effectively when the attack takes place.
As it is often said, an ounce of prevention is better than a pound of cure
- and this is very true in the case of DDoS. In the introduction, I had
mentioned that DDoS often happens because of vulnerable software/applications
running on a machine in a particular network. Attackers use those security
holes to compromise the hosts and the servers and install the DDoS
tools such as 'trin00'.
To prevent or mitigate future DDoS attacks, follow these steps:
To prevent your network from being used as a slave, follow these steps:
- Conduct regular audits on each host on the network to find installed
DDoS tools and vulnerable applications.
- Use tools like Rkdet, Rootkit
Hunter, or chkrootkit to find
if a rootkit has been installed on your system.
- Perform a general security audit on your systems on a regular basis:
- Keep your systems up to date to minimize software vulnerabilities (kernel and software upgrades)
- Check for rootkits
- Check logs for evidence of port sniffing, etc.
- Check for hidden processes by comparing the output of 'ps' and 'lsof'.
- Use auditing tools (i.e., Nessus,
SAINT,
or SARA)
- Check system binaries with, e.g., Tripwire to see if they've been changed since your last snapshot
- Check for open email relays
- Check for malicious cron entries
- Check /dev /tmp /var directories for odd files (i.e., '...', wrong permissions/ownership on device files, etc.)
- Check whether backups are maintained
- Check for unwanted users and groups (examine /etc/passwd)
- Check for and disable any unneeded services
- Check for SUID, SGID, and 'nouser' files on your system with the 'find' command
- Check the system performance (memory and CPU usage); note the average levels
- Create a DSE (Dedicated Security Expert) team for your company.
- Enforce and implement security measures on all hosts in the network.
The only hosts that should be allowed on your network are ones that have
been vetted by your security admin or DSE (Dedicated Security Expert).
All hosts on the network should be checked on a regular basis by your DSE team.
-
Collect your network and host data and analyze them
to see what kind of attacks are being run against your networks.
- Implement Sysctl-based protection. Enable the following in your '/etc/sysctl.conf':
# Enable IP spoofing protection, turn on Source Address Verification
net.ipv4.conf.all.rp_filter = 1
# Enable TCP SYN Cookie Protection
net.ipv4.tcp_syncookies = 1
Conversely, you could add this code to your '/etc/rc.local':
for f in /proc/sys/net/ipv4/{conf/*/rp_filter,tcp_syncookies}
do
echo 1 > $f
done
- Install PortSentry
to block scanning hosts.
- Add 'Mod_dosevasive' to your Apache installation. This is an Apache
module which performs 'evasive' action in the event of an HTTP DDoS attack
or brute force attack.
- Install the 'Mod_security' module. Since DDoS often targets HTTP
(port 80), it's a good idea to have a filtering system for Apache;
'Mod_security' will analyze requests before passing them to the web server.
- Set up load balancing for your services. In some ways, this is the
most powerful network-based defense against DDoS.
- Create awareness of security issues.
Conclusion
DDoS attacks can be mitigated at the target machine and prevented at the
slave network by implementing proper security. My advice to each and every
server and network owner is to implement effective security measures; since
DDoS is a network-wide problem, preventing it is going to require
everyone's help.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/cherian.jpg)
My name is Blessen and I prefer people calling me Bless. I got
interested in Linux when I joined the software firm, Poornam Info Vision Pvt Ltd also known as Bobcares. They gave me exposure to linux.
I am a B.Tech in Computer Science from the College of Engineering,
Chengannur. I passed out in the year 2001 and got into the company that
year. During my work, I was passionate with Linux security and I look
forward to grow in that field.
My hobbies are browsing net, learning new technologies and helping
others. In my free time I also develop open source softwares and one of
them is a scaled down version of formmail. The project is called "Smart
Mail" which is more secure than formmail.
 Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben is the Editor-in-Chief for Linux Gazette and a member of The Answer Gang.
Ben was born in Moscow, Russia in 1962. He became interested in electricity
at the tender age of six, promptly demonstrated it by sticking a fork into
a socket and starting a fire, and has been falling down technological
mineshafts ever since. He has been working with computers since the Elder
Days, when they had to be built by soldering parts onto printed circuit
boards and programs had to fit into 4k of memory. He would gladly pay good
money to any psychologist who can cure him of the recurrent nightmares.
His subsequent experiences include creating software in nearly a dozen
languages, network and database maintenance during the approach of a
hurricane, and writing articles for publications ranging from sailing
magazines to technological journals. After a seven-year Atlantic/Caribbean
cruise under sail and passages up and down the East coast of the US, he is
currently anchored in St. Augustine, Florida. He works as a technical
instructor for Sun Microsystems and a private Open Source consultant/Web
developer. His current set of hobbies includes flying, yoga, martial arts,
motorcycles, writing, and Roman history; his Palm Pilot is crammed full of
alarms, many of which contain exclamation points.
He has been working with Linux since 1997, and credits it with his complete
loss of interest in waging nuclear warfare on parts of the Pacific Northwest.
Copyright © 2006, Blessen Cherian and Ben Okopnik. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
Away Mission -- SDWest 2006
By Howard Dyckoff
This March conference, at the Santa Clara Convention Center, has been
the flagship conference of the CMP empire. This year SDWest offered the
usual solid matrix of developer tracks, but showed a growing emphasis on
security in software development. There were also a significant number of
sessions focusing on Agility in the development process, meaning that Agile
methods are becoming mainstream.
Not only did we have Scott Ambler [an industry-recognized software process
improvement (SPI) expert and contributing editor with Dr. Dobb's Journal]
discussing XP, RUP, and SCRUM in an evening BOF and Agile Modeling in a halfday
tutorial, but he also presented a technical session on Agile UP - Streamlining
the Rational Unified Process (RUP). In fact, there were 47 sessions referencing
"Agile" methods out of 235 total sessions including titles such as "Agile
Estimating and Planning", and "User Stories for Agile Requirements".
Another trend was the rise of AJAX. Almost as many sessions addressed this
REST approach to updating web pages as sessions focused on Web Services
[including WS-Security]. This is the paradigm du jour for new web development.
One of the surprises at the conference was seeing the last run by the
now-defunct Software Development magazine. The whole operation -- articles,
archives, conferences, etc -- are now under the Dr Dobbs logo. So future
conferences will be "Dr. Dobbs' SD Expo" conferences, and the URL "http://www.sdexpo.com" is redirected to
the Dr. Dobbs site. Although this is partly a rebranding effort, some of
the well-known staff personalities were not visible. I would speculate that
some other publications in the CMP stable may also do the consolidation
dance this year. [as a note of historical interest, "Software Development"
used to be called "Computer Language"]
This year, Microsoft's Visual Studio swept the awards. The VS product
manager, Rick LaPlante, went up a record 4 times for the Jolt awards. This
included Jolt's Best Product Award along with several others, including the
prestigious long-term Accomplishment Award. They also had one of the last
keynotes to present the new features of the award-winning VS Team System
product.
The VSTS demo showed integrated unit test refactoring, code coverage
checking, and result tracking. Everything goes into a data warehouse for team
access, and reports are available in Word and Excel formats. Also, VSTS has
wizards for building stress and performance tests which show bottlenecks via
automatic instrumentation. The final part of the demo showed linking TEAMprise
in a Linux environment to the VSTS repository -- impressive, and maybe something
that would catch your boss's eye, but the TEAMprise folks started as developers
of VS addins. TEAMprise is not primarily a Linux vendor.
For balance, Rails 1.0 won the Jolt award for Web Development Tools.
See the full listing of SDWest award winners here: http://www.ddj.com/pubs/sdmag/jolts/
Mechanical Turk
The best keynote also had the most intriguing title -- Artificial
Artificial-Intelligence and the Web. This was partly an introduction to Amazon's
experiment with with making public Web Services [and flexing its software
muscles], introduced by Amazon's WS evangelists Philipe Babrera and Jeff
Barr.
To tease our interest, the presenters retold the arcane history of the 19th
Century enigma, the Mechanical Turk. This was purported to be a mechanical chess
player seated at a chess board that could play winning games. In actuality, a
very small chess master controlled the mechanism from the trunk beneath the board
that supposedly housed the machinery. Because a human was in the mix, this was a
form of "Artificial Artificial-Intelligence" and Amazon has borrowed the name
for its new Web Service that links computers and humans.
The big idea is to use human interaction to understand input questions and
their context, aided by web automation.
Clients can ask for services at http://mturk.amazon.com [which is really
an asynch parallel network of human processors].
The task are farmed out to HITs -- Human Intelligence Tasks. The Web Service
organizes the tasks, allows human agents to volunteer for the tasks, collects
and forwards the results to the requesters. And all of this is organized by
micropayments of a penny or a dime or even a dollar a HIT.
On a practical level, Amazon had millions of photos of business addresses,
many similar and some just mislabeled. So they used the Mturk community to
verify and clean out inventory. They made small payments for each verifed or
corrected image and spent only a fraction of what the effort would have cost by
an outside agency. In effect they harnessed the intelligence and knowledge of a
large community of web users. Of course, some members of the audience were
concerned that this might create a legion of web wage serfs, working at or below
legal minimum wage.
A new company has organized itself around this service, http://askforcents.com. Currently they
are offering free requests as they workout the service details and business
model.
AJAX and REST
Christian Gross, Chair of SD Web Services Track, gave a back-to-back double
session on "Developing With AJAX and REST Patterns" to a full house. [ AJAX
represents the next generation of dynamic web development, Gross said. ]
REST is a development technique for Web Services using HTTP and, very often,
XML. REST has ruffled feathers in the Web Services world because of its 'simpler
is better' development strategy. For example, Ajax-Rest Components are agnostic
and do not require a file ending like .html, .aspx, or .jsp.
Besides examples of mash-ups and instantly updating sections of web pages,
Gross compared AJAX to technologies such as SOAP, and CORBA/DCOM/IIOP. Examples
and a short overview are available from: http://www.devspace.com:8088/. Also see
Christian's blog at devspace: http://www.devspace.com/index.php?paged=2.
For his Ajax Patterns Framework, try this link: http://www.devspace.com/~cgross/sources/snapshot/ajaxframework.zip.
And for a really detailed overview on AJAX, visit: http://www.telerik.com/default.aspx?pageid=2692.
Another gem of SDWest06 was the 2-day tutorial from C++ Experts Bjarne
Stroustrup and Herb Sutter. This required a special VIP or C++ Tutorial Pass for
attendance. It began with a 25th-anniversary keynote placing C++ in historical
and future context. Among other topics were new ISO C++ Libraries, C++(0x) and
the Concur Project, and Exception Safety. A full description is available here:
http://www.sdexpo.com/2006/west/tutorial.htm.
An added "Grab Bag" technical track included sessions such as "Essential
Virtual Computing Tips and Tricks" for VMWare and Virtual Server and "Open
Source ROI" which offered real world case studies. [Here is a link to the Open
Source Maturity Model that was discussed:
http://www.navicasoft.com/pages/osmm.htm ]
The Roundup....
Costs --- over $2000 for a full conference and tutorial pass, although
organizations can avail themselves of the "fourth person attends FREE" discount
for a net 25% savings. In comparison, pricing for EclipseCon and the MySQL User
Conference is under $1500. Of course, this is still less than the $2,495.00
Early Bird discount for conference and tutorials at JavaOne.
The Expo was small again, but featured a good mix of build tools, code
testers and software houses. There were raffles for Sirius satellite radios,
American Express checks, free software, and trainings. But by far the most
interesting was Macabe's instant lottery. They offered a check for $100,000
[!!!] if some one punched in the correct 6 numbers on a key pad. That would be
easy if you had 999,999 chances, or knew the previous entries, but no one did.
This year again SDWest conferencees got large black tote bags and again had
sandwiches each day in boxed lunches. On these points, EclipseCon was clearly
superior with a logoed backpack and full sitdown meals. Of course, EclipseCon
was much more narrowly defined - but that is also an advantage; it was all
Eclipse, all the time.
The best reason to come to the next SD Conference is the stellar cast of
developers and trainers who run the rich and detailed technical sessions. And
the broad scope and platform agnosticism is also refreshing. You can't eat those
things in many other conferences...
Talkback: Discuss this article with The Answer Gang
Howard Dyckoff is a long term IT professional with primary experience at
Fortune 100 and 200 firms. Before his IT career, he worked for Aviation
Week and Space Technology magazine and before that used to edit SkyCom, a
newsletter for astronomers and rocketeers. He hails from the Republic of
Brooklyn [and Polytechnic Institute] and now, after several trips to
Himalayan mountain tops, resides in the SF Bay Area with a large book
collection and several pet rocks.
Copyright © 2006, Howard Dyckoff. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
From Assembler to COBOL with the Aid of Open Source
By Edgar Howell
Introduction
Recently I had occasion to help convert an Assembler program into COBOL.
The Assembler part of it was familiar to me from the old days of IBM
Assembler 360/370/390, which was source-compatible with that used by
Siemens, Amdahl, and others at one time or another on so-called "big-iron".
For other than systems work, Assembler is gradually falling out of favor,
not without justification, based on some of what I have seen over the last
decade or so. Within this environment, COBOL is still a reasonable and
viable alternative.
The Problem
The program in question was well over 6000 lines of code -- 8000
with macro expansions -- and easily would have taken several weeks
to convert completely by hand. Only then could compilation and
testing start. A nightmare.
Fortunately, for many years one of the participants in the
project has been working on tools to improve the quality of
Assembler code as well as to convert it to PL/1 or COBOL. But it is
in the nature of Assembler that such a tool can never be finished.
Many of the Assembler programs I've seen in the past remind me of a
demolition derby: getting there is all that counts, it doesn't matter how
you do it!
I was given a copy of the Assembler program in which each
line had a unique line number, as well as a copy of the COBOL
program produced by software which had references to the line
number of Assembler code that caused generation of that particular
line of COBOL code. And "all" I had to do was review the generated
code and adapt it as needed. Hmmmm...
Manual Work
Had it only been necessary to make minor changes here and there,
likely the task would have been quickly finished. But there were
numerous places where something needed to be adjusted, often the
same problem, just a variation on a theme, and another place where
another change meant another chance of making a mistake.
To be sure, the vast majority of the software-generated code was
in excellent condition - but this isn't horseshoes. Even though the
customer will have to make final adjustments based on his operating
environment, it just wouldn't do to turn the final product over
with too many problems.
As it turned out, the biggest problem was that the software
faithfully produced COBOL code that replicated the Assembler code
very closely. Where the original code was clean, so was the
COBOL.
Assembler vs COBOL
Here is a small example of the problem. The following Assembler
code, which defines storage to manipulate the date (century, year, month
day) -
H1CYMD DS 0CL8
H1CYM DS 0CL6
H1CYY DS 0CL4
H1C DS CL2
H1YY DS CL2
H1MM DS CL2
H1DD DS CL2
resulted in the following COBOL:
01 H1CYMD PIC X(8).
01 filler6607 REDEFINES H1CYMD.
10 H1CYM PIC X(6).
10 filler6608 REDEFINES H1CYM.
20 H1CYY PIC X(4).
20 filler6609 REDEFINES H1CYY.
30 H1C PIC X(2).
30 H1YY PIC X(2).
30 filler6611-0 REDEFINES H1YY.
35 H1YY-char PIC X(6).
30 filler6611 REDEFINES H1YY.
35 H1YY-2-char PIC X(4).
20 H1MM PIC X(2).
10 H1DD PIC X(2).
Aside from the fact that this COBOL is pig-ugly, it isn't even
syntactically correct!
However, this is not due to the software but the Assembler code
itself: in the symbol table H1YY has a length of 2 because of its
explicit declaration with that length, but the REDEFINES H1YY-char
has a syntactically invalid length of 6 because that is the
explicit length used with it at one point in the Assembler program.
That's not syntactically incorrect in Assembler, but it is up to the
programmer to know whether that length is reasonable to use. Originally,
it was - but not in COBOL.
But there is no way I could have a chance of finding every
situation like that by hand. Now what?!
Open Source to the Rescue
The Norns have been very kind to me of late. A while back I had
discovered a COBOL complier for Linux but hadn't had the time to
investigate it. The problem with it was that since it wasn't part
of any distribution I had, I couldn't just grab an RPM and plop it
onto one of the machines and expect it to function.
It was now time to make time.
Installing Open COBOL under SuSE 10.0
As usual, nothing ever goes smoothly the first time - and
installing this package was no exception. In the following, I have
omitted the false starts, other than to demonstrate what to do if
that should happen to you. Basically, by not doing my homework up
front, I gained a certain level of experience at that. Do pay
attention to prerequisites when a package you are interested in is
kind enough to let you know in advance.
The documentation that came with Open COBOL listed the following
packages as required:
libgmp decimal arithmetic
libtool dynamic CALL statements
The following were optional:
libdb indexed file I/O and SORT/MERGE
libncurses SCREEN SECTION
Using YaST, I installed four of the following packages (listed as
required for development) that were available but not yet installed:
autoconf
automake
libtool present
gettext present
bison
flex
Installation then went as follows (indentation indicates a
different GUI window and CTRL-D exits root status):
mkdir /tmp/COBOL
cp /media/usb01/COB/open-cobol-0.32.tar.gz /tmp/COBOL/
cd /tmp/COBOL
tar xzf open-cobol-0.32.tar.gz
cd open-cobol-0.32
./configure
This failed because one of the required packages had not yet
been installed. No biggie, I just opened another window and
installed GMP.
mkdir /tmp/GMP
cp /media/usb01/COB/gmp-4.1.4.tar.gz /tmp/GMP/
cd /tmp/GMP
tar xzf gmp-4.1.4.tar.gz
cd gmp-4.1.4
./configure
This also failed since I hadn't anticipated doing any
"development" in this partition. So I fired up YaST and installed
gcc as well as glib2-devel and glib2-doc (instead of glib-* since
glib2 was already installed).
./configure
make
This took a tremendous amount of time to write endless messages
to the screen. Well, that is what you will think if you have never
run 'make' before.
su
make install
At this point you will need to note for later (export) the
messages regarding /usr/local/lib or whatever.
make clean
CTRL-D <end root status>
./configure
The following messages at the end are merely informative ("no"
due to absence of optional packages):
Use gettext for international messages: yes
Use Berkeley DB for file I/O: no
Use fcntl for file locking: yes
Use ncurses for screen I/O: no
make
su
make install
make clean
CTRL-D <end root status>
Initial Tests
The only thing left to do was to see if it had been worth all
the effort.
cd <directory_with_test_programs>
export LD_LIBRARY_PATH=/usr/local/lib
cobc hello.cob
./hello
Hello World!
After that I spent a bit of time playing around with what the
compiler can handle. Here you
can see a bit of code using decimal arithmetic -- which blew me
away! But, then, that is what the GMP package is all about.
That worked so well that I decided to dig out an almost
20-year-old test program from a COBOL package that worked under
MS-DOS. Minimal compiler error messages. And after I made comments
of a couple of lines of code, the program compiled. And executed!
Like access to the date and time in the machine, output to the
screen, input from the keyboard. And I didn't have to change
anything!
The Acid Test
OK, so it's time to see if this thing can help me with my
real-world problem. I fed it the program I had been working on and
among the error messages were:
/tmp/temp.cob:2081: size of 'filler6611-0' larger than size of 'H1YY'
/tmp/temp.cob:2083: size of 'filler6611' larger than size of 'H1YY'
I'm a believer!
Conclusion
While I may never have need to do any program development with this
COBOL compiler, in a very brief period of time it has made a big impression
on me. It seems to produce good code, although divide by zero didn't give
the response I expected. Still, the ability to deal with
decimal arithmetic is very impressive.
It seems to be very good at discovering syntactic errors in source code.
I spent considerable time finding and fixing minor syntax problems that I
never ever would have found just by reading the code. Exactly what I had
hoped for.
And it ought to be perfect for anyone wanting to learn COBOL at home
without the time pressure or expense of a formal class somewhere.
Due to dependencies, installing Open Source programs can turn into a bit
of a pain, particularly if the discrepancies between your system and the
requirements of the package are too great. But within reason this can be
overcome, as you saw above. And in all likelihood, the accompanying
documentation will let you know what is needed.
It can certainly be worth your taking the time to try out that
package of interest.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/2002/note.png) Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
Edgar is a consultant in the Cologne/Bonn area in Germany.
His day job involves helping a customer with payroll, maintaining
ancient IBM Assembler programs, some occasional COBOL, and
otherwise using QMF, PL/1 and DB/2 under MVS.
(Note: mail that does not contain "linuxgazette" in the subject will be
rejected.)
Copyright © 2006, Edgar Howell. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
Plotting time series data with Gnuplot
By Ron Peterson
Introduction
Good systems administrators log stuff. Lots of stuff. A lot of the
information we collect consists of time series data: a set of numerical
values assocated with a sequence of discrete time values.
There are any number of tools to help the diligent sysadmin monitor
this data visually as it is collected. A good many of them are built
using Tobias Oetiker's excellent RRDTool.
Some noteworthy examples include Cacti, Cricket, and Smokeping. There
are many others.
That's all well and good as long as you know what you want to
monitor. However, sometimes you'd just like to do some quick ad hoc
visualization. As you might surmise, most Linux systems provide a myriad
of visualization tools (Grace and GRI come to mind). In this
article, I'll introduce you to Gnuplot, focusing specifically on
how to plot time series data.
Prepare some data
Gnuplot without data is like gravy without potatoes. So before we
get to the gravy, let's make some potatoes. Let's say for the sake of
argument, or at least for the purpose of giving the rest of the article
something to talk about, I include the following line in my system's
crontab file:
*/1 * * * * root /bin/cat /proc/loadavg 2>&1 | /usr/bin/logger -p local3.info -t CRON-LOADAVG
If you're like me, and have configured your system's syslog.conf as
follows:
local3.* /var/log/cron.log
...then you will find all local3 facility messages in their own
special file. Because we're telling 'logger' to tag all of our load
average data, it will be easy to extract this information from the rest
of our logfile clutter. A simple 'grep CRON-LOADAVG /var/log/cron.log >
load.dat.1' should do nicely. This will give us a file that looks like
so:
Mar 19 00:30:02 ahost CRON-LOADAVG: 0.40 0.78 1.19 11/296 3690
Mar 19 00:31:01 ahost CRON-LOADAVG: 3.54 1.55 1.41 4/311 3997
Mar 19 00:32:01 ahost CRON-LOADAVG: 2.68 1.59 1.43 2/278 4142
...
Now let's extract just the data we want:
cat load.dat.1 | tr -s ' ' ' ' | cut -d' ' -f1,2,3,6 > load.dat.2
The translate command 'tr' squishes multiple spaces into a single
space, so that we can expect more consistent behaviour from the 'cut'
command. In this case, the translate command 'tr' is superfluous, but
I think it's a good habit nonetheless. With any luck, our data now
looks something like:
Mar 19 00:30:02 0.40
Mar 19 00:31:01 3.54
Mar 19 00:32:01 2.68
...
That's almost perfect. Unfortunately, our gnuplot example will
expect two space delimited columns of input, so we need to replace the
spaces delimiting our timestamp components with some other character,
like a hyphen.
perl -pe 's/(.*?)\s(.*?)\s(.*)/$1-$2-$3/;' load.dat.2 > load.dat.3
This isn't a Perl article, so I won't bore you with the details of
what this command is doing. In the interest of pedagogy though, I think
it's helpful to illustrate how sausages are sometimes made; even if it
does make me look like a butcher. Our data now looks like:
Mar-19-00:30:02 0.40
Mar-19-00:31:01 3.54
Mar-19-00:32:01 2.68
...
Plot it
Now it's time for the gravy. First I'll give you a taste, and then I'll
explain the recipe. Create a file with the following contents,
excluding the line numbers. Call it 'plot-load.conf'. Edit the date
range on line six to include the extents of your data.
1 set terminal png size 1200,800
2 set xdata time
3 set timefmt "%b-%d-%H:%M:%S"
4 set output "load.png"
5 # time range must be in same format as data file
6 set xrange ["Mar-25-00:00:00":"Mar-26-00:00:00"]
7 set yrange [0:50]
8 set grid
9 set xlabel "Date\\nTime"
10 set ylabel "Load"
11 set title "Load Averages"
12 set key left box
13 plot "load.dat.3" using 1:2 index 0 title "ahost" with lines
If you run the following command, you should end up with a file
called 'load.png'. Use your favorite image viewer to take a look.
Hopefully nothing too alarming shows up.
cat plot-load.conf | gnuplot
The first line of our gnuplot command file says to create a PNG file,
and gives its dimensions. PNG is only one of a myriad possible output
formats. The second line says our X axis represents time data. The
third line uses standard date format specification (see 'man date') to
indicate what our data file's timestamp data looks like. We must use
the same format in line six, where we indicate our graph's start time
and end time. You can omit this, but I find it's useful to anchor the
endpoints, particularly when plotting multiple data sources in a single
graph. Line seven sets the plot limits of our Y axis.
Line 13 deserves a little bit of extra attention. The name of our
data source comes first. The 'using 1:2' bit means to extract data from
columns one and two of our data source. The 'index 0' bit means to use
the first data set in the file. Data sets are delimited by pairs of
blank records. Our file was simple. It only comprised col1 and col2 of
data set zero in the following pseudo data file.
# data set zero
col1 col2 col3 col4
col1 col2 col3 col4
col1 col2 col3 col4
# data set one
col1 col2 col3 col4
col1 col2 col3 col4
col1 col2 col3 col4
col1 col2 col3 col4
# data set two
col1 col2 col3 col4
col1 col2 col3 col4
col1 col2 col3 col4
Asuuming we had multiple data sets in a single file (perhaps we want
to compare load averages from multiple hosts), one way we could combine
this data into a single graph would be to expand our line 13 as
follows:
plot "load.dat.3" using 1:2 index 0 title "ahost" with lines, \
plot "load.dat.3" using 1:2 index 1 title "bhost" with lines, \
plot "load.dat.3" using 1:2 index 2 title "chost" with lines
Conclusion
Potatoes are nice, but as Trotsky once noted, they are "the classic
symbol of poverty". Knowing how to quickly whip up some time series
plots is useful, but Gnuplot is capable of far more than I've even
hinted at in this article. Hopefully I've managed to whet your appetite
to learn even more.
Best.
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/peterson.jpg)
Ron Peterson is a Network & Systems Manager at Mount Holyoke College in
the happy hills of western Massachusetts. He enjoys lecturing his three
small children about the maleficent influence of proprietary media
codecs while they watch Homestar Runner cartoons together.
Copyright © 2006, Ron Peterson. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
Digging More Secure Tunnels with IPsec
By René Pfeiffer
Introduction
In my last article about IPsec we
learned about the building blocks of IPsec in the Linux kernel. We took a
look at the tools needed to build encrypted and secured data paths between
two hosts. Now we'll use this knowledge and move a step further on.
IPsec is often used to connect two or more different networks by using
tunnels. If you have a complex setup, then exchanging keys manually and
keeping track of them can get very challenging. IPsec offers a way of
handling keys automatically. Let's take a look how this works.
Entering the Tunnels
We already know how to encrypt all data between two hosts. We created the
keys and put them into the setkey.conf file, where we also
configured our security policy that tells the kernel to use IPsec between
the IP addresses of our hosts. When using IPsec for remote access purposes,
it is far more useful to reach a whole network of hosts than only one IP
address. You can do this by using IPsec's tunnel mode. Let's assume that we
have two networks named A and B. Both are "behind" two gateways named
after the nearest connected network. The classical way to connect both
networks is to install a route on both gateways. This means that every
packet between network A and B travels unencrypted through the direct
connection.
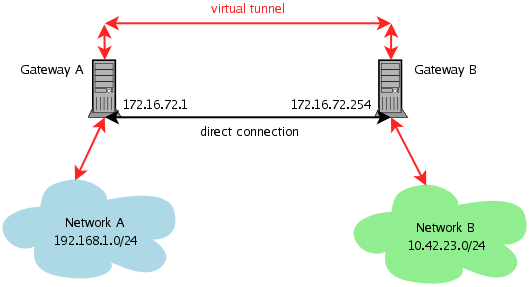
We want to use IPsec instead. This means that both gateways still need to
see each other, and we still have the direct connection. In addition to
that, we get a "second" way our packets can travel. We call this connection
a virtual connection or tunnel. Only the tunnel holds our packets
travelling between network A and B. They are encapsulated into ESP or AH
packets. The direct connection holds the corresponding IPsec packets (i.e.
the AH and ESP packets itself). You have to keep this in mind when creating
configurations. Compared to the two single host scenario we have more
addresses involved. We need the gateway and the network we want to connect
to. If you know this information, then you can begin to create an
appropriate entry for the gateways' Security Policy Databases (SPD).
#!/usr/sbin/setkey -f
#
# SPD for gateway A (172.16.72.1)
#
spdadd 192.168.1.0/24 10.42.23.0/24 any -P out ipsec
esp/tunnel/172.16.72.1-172.16.72.254/require
ah/tunnel/172.16.72.1-172.16.72.254/require;
spdadd 10.42.23.0/24 192.168.1.0/24 any -P in ipsec
esp/tunnel/172.16.72.254-172.16.72.1/require
ah/tunnel/172.16.72.254-172.16.72.1/require;
Let's start with the first
spdadd line. It tells the kernel the
following: if you see a outbound packet going from our network
192.168.1.0/24 to the network 10.42.23.0/24, then use IPsec encapsulation
and transport the encapsulated data from our external address 172.16.72.1
to the machine with the address 172.16.72.254. The keyword
require
tells the kernel that IPsec encapsulation is mandatory. The second line
defines how to handle the return traffic. Rephrased it says: if you see an
IPsec encapsulated inbound packet coming from the network 10.42.23.0/24 and
going to our network 192.168.1.0/24 and this packet is coming from the
gateway 172.16.72.254 to our external address, then undo the IPsec
encapsulation. These are the policies we need for our tunnel. It sounds
complicated, but if you take the diagram and trace the packet flow, you
will see that it is just a description of what the kernel should do. We now
need the keys. We'll reuse the ones from the last article.
# AH SAD entries with 160 bit keys
add 172.16.72.254 172.16.72.1 ah 0x200 -A hmac-sha1 0x46915c30ed7e2465b42861b6ab19f2772813020c;
add 172.16.72.1 172.16.72.254 ah 0x300 -A hmac-sha1 0xc4dac594f8228e0b94a54758f7fbf2fdf4e37f3e;
# ESP SAD entries with 192 bit keys
add 172.16.72.254 172.16.72.1 esp 0x201 -E rijndael-cbc 0xa3993b3dfc41ef0a1aa8d168a8bf2c27e48249ac17b61e09;
add 172.16.72.1 172.16.72.254 esp 0x301 -E rijndael-cbc 0x8f6498928ba354bd45cfad147f54c67b3b742896b3bafc02;
Again this tells the kernel which keys to use when to go from one gateway to another. You have one
line for outbound traffic and one for inbound traffic. Now go ahead and create the configuration on
both gateways. You can create one
setkey.conf and mirror source and destination for the other
gateway since packet flows are symmetrically reversed. Enter the command
setkey -f /path/to/setkey.conf
on both gateways and try pinging, telnetting or tracerouting to the network "on the other side".
One word about the example setup: I set the gateways' IP addresses so that
they're near each other in IP space; this is something you need to do when
routing with directly-connected gateways. When using IPsec tunnels, the
gateways don't have to be physically connected, and you can create IPsec
tunnels between any hosts and networks that "see" each other on layer 3 (IP
in our case).
Routing and the Kernel Policy
Maybe you have noticed that we didn't set any routes to the networks we
connected. We don't need to. We told the kernel already what to do with
the packets. The Security Policy Database takes care of the packets' path.
This behaviour has some implications you have to consider. First, whenever
using IPsec tunnels your networks can be "contaminated" by packets with an
origin IP outside your network. This is actually what you usually want, but
it is very important to consider it in order to implement good access
control. If a server in network B only expects and allows connections to be
from 10.42.23.0/24, then clients in network A cannot access these services.
This can be either good or bad. In any case you have to be aware (and
possibly take care) of that. This leads to the second consideration -
security. When building one or lots of VPN tunnels, you have to be careful
where your endpoints are and what networks they can see.
Automatic Keying and X.509 Certificates
Digging multiple tunnels, dealing with many IPsec clients and keeping track of the keys is a big
problem. Consider a gateway that expects IPsec connections from 10 other systems. Then the setkey.conf
gets a bit crowded and no one will want to maintain long hexadecimal numbers. In addition to that,
pre-shared keys are best used with fixed IP addresses. If you obtain IP addresses dynamically, then
you have to think of something else.
Fortunately there is a solution for this problem. The Internet Security
Association and Key Management Protocol (ISAKMP) is part of IPsec. It was
designed "for establishing Security Associations (SA) and cryptographic
keys in an Internet environment", to quote the RFC. It can help us with
exchanging keys and creating security policies for the Linux kernel. Key
exchange and creation of an IPsec connection are broken up into different
phases.
- Phase 1 is a setup phase, also called main mode. The two
partners work out how to exchange information securely. They negotiate the
encryption method, the hash algorithm, the authentication methods, and a
way to securely exchange encryption keys for the next phase. The result of
phase 1 is a "security association" that tells both partners how to
communicate securely.
- Phase 2 includes the creation of the security policies for the AH and
ESP protocols. That's what we already did manually.
During phase 1 the two IPsec partners also check whether they have the
right keys to talk to each other. The real data transmission starts after
phase 2 is completed.
In order to use ISAKMP you have to configure the racoon
daemon. It is also part of the ipsec-tools package. Its configuration file is typically found at
/etc/racoon/racoon.conf. We will recreate the tunnel above with racoon in order to get
to know the most important configuration directives.
While we are at it, we will swap the pre-shared keys for X.509
certificates. This makes life easier when maintaining multiple keys or
issuing VPN access to clients. The certificates are used in the same
familiar way as SSL certificates on the World Wide Web, a combination also
known as HTTPS (encrypted HTTP). Instead of creating long strings, you
simply create a self-signed SSL certificate. Your IPsec gateway(s) check
these certificates against the public key of your own Certificate Authority
(CA). Every certificate signed by your own CA opens a IPsec tunnel, just
like a key would. You can now give these certified keys to every host that
is allowed to talk IPsec to you. While this sounds more complicated, it
really gets easier when dealing with a lot of IPsec clients.
Automatic Keying in Action
Let's rebuild the last example with racoon. It starts like this:
# racoon.conf file for gateway A
#
path certificate "/etc/racoon/certs";
path pre_shared_key "/etc/racoon/psk.txt";
log notify;
listen {
isakmp 172.16.72.1 [500];
};
The first directive tells
racoon where to look for certificates and
certified keys. In our case, this is the directory
/etc/racoon/certs. Then we tell the daemon where to look for a
collection of pre-shared keys (PSKs). You can use PSKs as well, you don't
need to use certificates. The file
/etc/racoon/psk.txt holds a list
of unique identifiers (such as hostnames or IP addresses) and their
corresponding keys.
The next line sets the log level. The log level can be either
notify, debug or debug2. Increase the log level if you
want to see how racoon creates the IPsec connection. All logging
goes to syslog. The listen directive tells racoon where to
listen for ISAKMP requests. By default it listens on all devices and on
port 500/UDP (the default port for ISAKMP). So far, so good. Now we define
the path to gateway B.
remote 172.16.72.254 {
exchange_mode main;
generate_policy off;
passive off;
certificate_type x509 "gateway.a.example.net.cert" "gateway.a.example.net.key";
ca_type x509 "ca-cert.pem";
my_identifier asn1dn;
peers_identifier asn1dn;
verify_identifier on;
proposal {
encryption_algorithm 3des;
hash_algorithm sha1;
authentication_method rsasig;
dh_group modp1024;
}
}
Let's walk through the options and see what they mean.
- exchange_mode main - defines the key exchange mode. main is a good choice since
it is considered more secure.
- generate_policy off and passive off - when using automatic keying one gateway
acts as initiator of the IPsec link. The other gateway remains passive and answers the requests of
its peer. By using these two directives we define gateway A to be the initiator of the link. Gateway
B need the options generate_policy on and passive on to answer.
- certificate_type and ca_type - indicate the type of certificates we use. We use
X.509 certificates and racoon needs to know our key, our certificate and the public certificate of our CA.
Even though we're using IP addresses for our gateway definitions, make sure that you use hostnames in the
certificates and keys. This is good practice.
- my_identifier and peers_identifier - indicate which identifier should be used to
identify hosts or IPsec endpoints. You can use either IP addresses, fully-qualified domain name,
ASN.1 distinguished names (ASN.1 DNs) or self-defined IDs. We use ASN.1 DNs since our certificates
contain them anyway.
- verify_identifier on - means that we wish to verify our peer's identifier by checking
the certificate with our CA.
- proposal - this section holds all information for the phase 1. You can define encryption
and hash algorithm, authentication method and Diffie-Hellman exponentiations for secure key
exchange. The authentication method is rsasig when using certificates, use
pre_shared_key for pre-shared keys.
The man page of
racoon.conf has a full list of options and parameters. My example boils down
to the bare bones. Keep in mind that we need the configuration above for phase 1 of our connection.
We still need to define the security policy for phase 2. This is done in a separate block.
sainfo address 192.168.1.0/24 any address 10.42.23.0/24 any {
pfs_group modp1024;
encryption_algorithm aes;
authentication_algorithm hmac_sha1;
lifetime time 28800 sec;
compression_algorithm deflate;
}
The first line announces that the policy is valid for all packets originating in the 192.168.1.0/24
network and going to the 10.42.23.0/24 network.
- pfs_group modp1024 - is used as a parameter for the Diffie-Hellman algorithm.
- encryption_algorithm aes - selects the AES encryption algorithm. You can specify more
than one algorithm. One will be chosen during phase 2.
- authentication_algorithm hmac_sha1 - select the authentication algorithm. Again you can
specify more than one.
- lifetime time 28800 sec - tells racoon how often this security policy
needs to be renegotiated.
- compression_algorithm deflate - selects a compression algorithm. Currently there is only
one implemented.
We don't need to define the return path policy since our peer already encapsulates inbound packets
with IPsec.
That is the whole
racoon.conf configuration. You need to
have another on gateway B. Make sure that the IP address in the
remote section corresponds to
the correct peer and that the networks in the
sainfo section are reversed. As soon as you
have everything in place you can test the setup. Start the
racoon daemon on both gateways.
On most systems you can do this by issueing the command:
/etc/init.d/racoon start
Check the logs. Most probably not much will happen. The IPsec connection will be initiated by the
gateway with the option
passive off enabled. Use a client on this gateway's network and
create some traffic to the network you wish to connect to via the tunnel. After the first packets are
sent, the
racoon daemon will start ISAKMP and negotiate through phase 1 and 2. If everything
goes well, you can send your first ping packets through the tunnel. The tunnel may needs some seconds
to come up. You will get messages such as "resource temporarily unavailable" if the tunnel is
not yet ready.
Mobile Tunnels for Roadwarriors
IPsec tunnels are frequently used to connect mobile clients "on the road". They connect to a central
gateway, sometimes called a VPN or an IPsec server, and create a secure tunnel. You can use
our racoon.conf files with some modifications. Your IPsec server needs to be in passive mode
since it's waiting for incoming connections. The connections can originate from anywhere, so your peer will
be anonymous.
remote anonymous {
exchange_mode main;
generate_policy on;
passive on;
certificate_type x509 "vpnserf.example.net.cert" "vpnserf.example.net.key";
ca_type x509 "ca-cert.pem";
my_identifier asn1dn;
peers_identifier asn1dn;
verify_identifier on;
proposal {
encryption_algorithm 3des;
hash_algorithm sha1;
authentication_method rsasig;
dh_group modp1024;
}
}
The rest of the options can stay the same except for
generate_policy and
passive. Both
need to be enabled.
generate_policy tells
racoon to create new policies for new
connections; this makes sense because our peer varies. The same considerations need to be applied to
the security policy in phase 2.
sainfo anonymous {
pfs_group modp1024;
encryption_algorithm aes;
authentication_algorithm hmac_sha1;
lifetime time 1 hour;
compression_algorithm deflate;
}
It is a good idea to reduce the lifetime for mobile peers. Again, the parameter
anonymous lets
racoon accept varying policies. The configuration of the mobile client has to specify
the IPsec server's address and the security policy to our internal networks.
Next time we will take a look at filtering IPsec traffic and protecting exposed IPsec servers.
Happy digging!
Further Reading
Talkback: Discuss this article with The Answer Gang
![[BIO]](../gx/authors/pfeiffer.jpg)
René was born in the year of Atari's founding and the release of the game Pong.
Since his early youth he started taking things apart to see how they work. He
couldn't even pass construction sites without looking for electrical wires that
might seem interesting. The interest in computing began when his grandfather
bought him a 4-bit microcontroller with 256 byte RAM and a 4096 byte operating
system, forcing him to learn assembler before any other language.
After finishing school he went to university in order to study physics. He then
collected experiences with a C64, a C128, two Amigas, DEC's Ultrix, OpenVMS and
finally GNU/Linux on a PC in 1997. He is using Linux since this day and still
likes to take things apart und put them together again. Freedom of tinkering
brought him close to the Free Software movement, where he puts some effort into
the right to understand how things work. He is also involved with civil liberty
groups focusing on digital rights.
Since 1999 he is offering his skills as a freelancer. His main activities
include system/network administration, scripting and consulting. In 2001 he
started to give lectures on computer security at the Technikum Wien. Apart from
staring into computer monitors, inspecting hardware and talking to network
equipment he is fond of scuba diving, writing, or photographing with his digital
camera. He would like to have a go at storytelling and roleplaying again as soon
as he finds some more spare time on his backup devices.
Copyright © 2006, René Pfeiffer. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
Column: IT's Enough To Drive You Crazy
By Pete Savage
Pete has the good fortune to be employed - which
includes the bad fortune of having to wrestle with an outdated operating
system on a regular basis. In order to stay sane - although some, including
perhaps Pete himself, would argue the term strenuously - he a) uses Linux
on his own time, and b) rants about his trials and tribulations here in the
Linux Gazette, where we're happy to help a fellow Linux user escape the
less-sublime facets of his non-Linux reality. (Face it: most of us would
drink heavily or kick defenseless puppies. Pete's coping skills
rock.)
-- Ben
So we come to the second article in the now-serialised, "IT's Enough To
Drive You Crazy". I pondered on whether the previous article was a
one-off, or whether it was something that would be happening on a regular
basis. The optimist inside me cried "One-off, one-off"; the realist,
however, took to hiding in a tiny corner of my mind, right after scrawling
a hand-written note that said, "You will never escape." Well,
give that man a pie - he was actually right. After a short consultation
with my editor, he decided that it would probably be beneficial to my
psychological state to vent my anger in a quiet and constructive way, such
as writing an account of everything that happened. "Like a diary?" I
chirped. Exactly. I dug out my Transformers note book, complete with
'Skool is Cool' stickers (remember those?), and prepared to write. I hoped
it would take me several days before I would have to write in it. I was
wrong.
I was caught early on Monday by a colleague who wanted to print something.
On inquiring what was wrong with his printer, I was told that it was
broken. On any normal day, this would probably mean that the OS in
question would have forgotten what printer was attached, and would probably
refuse to acknowledge that any kind of printing device was attached to the
computer at all. It gets to the point where sometimes you want to take the
advice of some of the computer comedians and plug a webcam into the
computer to actually demonstrate how ridiculously stupid it is being.
Owing to the fact that I didn't have a webcam, as well as the the imminent
danger of my colleague's head exploding, I opted for a more surefire
approach: I unplugged the printer from one USB port and plugged it into a
different one. The next thing that happened both confused and infuriated
me, though it wasn't something that was new to me: the printer was detected
and installed as "Canon i9100 (2)". 'But I already have a "Canon i9100"!',
I screamed, 'Why can't we use the same one?' There were six USB ports on
this machine. I resisted the temptation to try each individual USB port,
and put it down to the fact that the machine obviously had disowned USB.
Maybe it was fed up with all of those USB 2.0 devices that could perform
faster.
To cut a long story short, the printer still didn't print; my colleague's
head actually exploded, which almost negated the need for printing the
document; the printer ran off whimpering into the corner; and I lost all
faith in this OS's ability to handle USB. My decapitated colleague handed
me a USB stick. "It's stored on 'ere, can you print t'off that instead?"
Does a chicken have wings? I assured him that it would all be fine and
that I would have his documents ready on time. Not that it's my job to
print them, but I'm a nice guy, right?
Tuesday started worse. I entered my office and sat down at my desk. As part
of my morning ritual, I let out a large sigh, which I always seem to do at
7:39 in the morning. I took the USB stick I had been given yesterday, and
leaned over to gently insert it into my machine. I ignored the
spaghetti-like mess which appeared to be leaking out of all electrical
appliances in the office and congregating around my computer. Then, the
sort of premonition I described the last
time occurred again (I suppose I really must find a name for it - how
about a MOIDAF? That is, a Moment Of Impending Doom And Frustration.) I sat
back up, took a sip of water and waited for the familiar, "You are
obviously too damn lazy to open the drive up yourself, so let me do it for
you" prompt to appear. It never did. I took out the USB stick and tried
again. Vague memories of the previous day entered my mind and I was
forced, against all better judgment, to try another USB port. Still
nothing. My machine still sat in a state of some confusion at the object
which had just been inserted into it. It seemed to be treating it like
some kind of annoying pest, and ignoring it.
I eventually figured out what was wrong. It was simple, really: my
computer had suffered a bout of selective amnesia and simply forgot it had
a USB device attached at all. How useful. Apparently this kind of thing
is not uncommon. If I had been given some kind of explanation for this, I
may, and I repeat may, have forgiven it just this once. After a
trip to the control panel, the USB port was found again - surprisingly -
and all was well. The unanswered question from this experience, however, is
"what drove my computer to disown its USB ports in the first place?" I had
no logs to check, no way to see what drivers were loaded into the system
- and hence, no way to find out what the hell had caused this medical
disorder. I do hope it isn't catching. Had I been using my Linux box, I
would have a plethora of logs, events, and such. I could have even run an
'lsmod' command to find out what drivers were loaded, followed by the
possibility of a 'modprode' command to reload the USB driver. I'm fed up
with people inventing excuses for operating systems.
"It's a Thursday. It never works well on a Thursday."
"Everyone else's seems to do the same thing, I thought it was normal
for it to do that."
"I think I scared it when I talked about Linux in front of it
yesterday."
"It likes to hog all system resources, that's just it's thing."
Why should we as users have to create excuses for an operating system
that should be designed with us in mind? [1]
Sorry, you must forgive my pedantic babbling. Some would say it comes with
the territory, others would say I'm just a grouch. I like to think I'm
somewhere in between. Now, where was I? Ah, yes. Wednesday. It strikes me
as odd that this particular problem could have evaded all pursuit as long
as it has, through the entire operating system history. I'm not pointing
any fingers with this one, primarily because I don't have enough fingers or
toes to be able to.
In the company I work for, certain departments collaborate heavily on
particular projects, which I must say is excellent and I actively
encourage. The problem arose from the requirement to transfer a very large
structure of data from one server to another. "A simple copy and paste," I
hear you cry, "or a complicated mirror?" This time I opted to just stick
with the tried and tested drag-and-drop approach: click on folder with
lots of stuff in it. Drag it over folder which has not so much stuff in
it. Drop folder. Pray. The copying started and I sat back with a smug
feeling of satisfaction, it was 3:30 after all. My satisfaction was
short lived (was that really going to be such a surprise?) At 3:32, the
copying stopped. Not because it was finished, or because it wanted to
take a short coffee break; not because I had told it to, or because it
was hungry. No. It stopped because there was a problem. I have a
vision of you faithful readers all sitting round me like kids listening
to a story at primary school, leaning forward in anticipation. Why did
it stop? There was a problem. And this problem was not described well
or accurately, no. It was described by one word which throws fear into an
IT professionals heart: 'ERROR'.
Turns out it couldn't copy one of the files, aww, bless. So instead of
keeping this information safe and carrying on with the rest of the copy
routine, it decided to do the sensible thing: cry like a baby and throw
the copy operation out of it's pram. I had to spend the next 15 to 30
minutes copying small portions of the tree across till I encountered
the error again, then traversing the directory tree and repeating the
procedure. It turned out one of the files had a name that was too
long. For goodness sake! If you are going to create a file system
that people are actually going to use, that's right... real people, not
just geeks, why not build in protective routines to prevent this from
happening? It's like building a bridge that's only connected to the
ground at one end, watching cars go over the other end to their doom
and saying, "well, if they will try and go right to the end, what do you
expect?" Users are going to try to create files with stupid names like
"Letter I wrote to the gas board when they cut my gas off because they
said I forgot to pay it, but I thought I had (third time).doc"
<rant>
Users don't sit there and remember the maximum number of characters a file
name, including its full path, can have. They don't count characters as
they type them or obey conventions by not using spaces and full stops in
file names. Users are there to use a computer, I do not
believe they should be expected to do their own input validation. After all,
that's what a computer is for - isn't it?
</rant>
Don't you just love going into a High Street computer hardware store
and quizzing the sales teams? It's fascinating watching them skitter
up to people and inquire if they need assistance. If the customer
responds in a way that indicates anything other than "I'm just looking,
thanks", they lean over towards them with that kind of inquisitive
expression normally worn by small rodents. They contort their faces
and look confused until they hear one of the buzz words that had been
batted around in the training camp. Then they lean back and smile,
confident in the knowledge that they have a whole paragraph with which
to blind the unsuspecting 68 year old woman buying a joystick for her
grandson.
"Oh, you want to buy this one," he'll say. "It's ya basic 3 axis controller
with 512 quantization steps in linear movement, complemented with linear
throttle control, eight buttons, HAT controller and connects to any
standard MPU-401 or USB port if you buy the optional converter. Does your
grandson have an MPU-401 port or is it one of the newer USB ports?"
Dear Old Lady: "Well, I just don't know. He got one of these computer
somethings for his birthday. He can watch films on it, does that
help?"
Salesman: "Hmmm, well if I were you, I'd buy the converter as well. You
don't want him to be disappointed, DO YOU? Do you want to purchase
our exclusive joystick cleaning cloth as well?"
On this particular day, a Thursday as it happens, I decided to wander
into one of these High Street stores. I was looking at a rather
strangely shaped case when one of our little friends popped his
quivering nose into my face.
"S'a good machine that one. Got the latest Intel Pentium processor
with HT technology in it. I've got one at home." I looked at him,
with a rather impressed look on my face, trying to hold back the
laughter. [2]
"Oh really?" I replied, just begging for more information. "So what
does HT stand for?"
His face immediately changed to that of someone try to remove a
particularly chewy toffee from their teeth, whilst keeping their mouth
shut.
"Hy... Hy... HYPO-THRIDDING!!!" The words suddenly leapt from his mouth.
I almost swallowed my chewing gum.
"Hypo-Thridding, eh? So what does this do, compared to one which
doesn't have," (I had to say it again) "Hypo-Thridding?" I waited.
"Well it's... just... better, really." He replied.
"Better how?" I asked. I could tell he was near breaking point.
"Well... it's... more expensive, so it has to be better!" was the
reply.
"Right... so the fact that, HYPER THREADING, that's HYPER-THREADING, can in
certain circumstances increase the performance of the processor by
providing usually idle execution units with useful work was just something
Intel put in as a bonus, was it?" My little rodent friend scurried away.
Oh, what a week. This was the last day, "only eight hours till the
weekend!" I thought. I was wrong. I was called up late in the evening to
fix a friend's PC which had a dodgy HDD. He'd purchased a new one and
wanted some assistance fitting it and recovering his system. The data was
all backed up and I was presented with a fairly easy task - you might think.
The HDD was installed without a hitch. I was handed the recovery CD and
duly inserted it into the CD drive like the happy little camper I was.
Almost the weekend - YAY! I clicked the big recover button, and assured the
utility that I was actually aware that doing so would remove all the data
from my HDD.
"Sorry, the system doesn't match the original."
My visions of an easy half hour catching up on some reading were shattered.
Normally, that's where the journey would end for most non-Linuxian users -
but I had a few tricks up my sleeve. I knew the old HDD still functioned
but seemed to go haywire every now and then, so I restored the OS back to
the old HDD, booted up faithful Knoppix, split the new larger HDD into two
partitions using 'fdisk', and used 'dd' to copy the data from the old one
back to the new one. Once that had finished, which took several hours
owing to the fact that 'dd' copies every bit of data from one drive to the
other whether it's being used or not, I simply shut down the machine,
removed the old HDD and my flexible friend Knoppix, and booted the PC back
up again.
I can hear some of you saying, "but the problem was fixed, Pete. What are
you complaining about this time?" I'm complaining about the injustice
done to the average non-geek computer user. What do they do when
they can't upgrade their computer? Return to vendor to buy new PC. When
the HDD breaks and it's no longer under warranty? Return to vendor to buy
new PC. I suddenly visualised the massive corporate troubleshooting
flow diagram - the flow diagram to end all flow diagrams. It was a
highly conceptual diagram, for to print it would have leveled half of
the African rain forest. On it was detailed every single problem a user
could ever encounter, all of which were gracefully solved. The flow
paths wound their way towards the bottom of the flow chart. Which
ended in a single instruction. "A single instruction that would solve
all problems?" I hear you cry. Yes, I reply.
"Return to vendor to buy a new PC."
[1] At this point, I would like to
ask if anyone has a good reason why we should be creating these excuses, or
if you yourself have a favorite excuse, pass it along to me. You won't win
anything, or be given a prize for the best excuse, as chosen by our panel
of dysfunctional judges, but you can go away with the feeling that you have
helped make the world a better place.
[2] They've always got one at home,
ever noticed that? It doesn't matter what product it is, plasma television,
kettle, latest games console, portable bread maker, you can go into the
shop safe with the knowledge that every salesperson there will have one at
home, or have a close relative who's just got one for their birthday. I
must be in the wrong job.
Talkback: Discuss this article with The Answer Gang
Pete has been programming since the age of 10 on an old Atari 800 XE.
Though he took an Acoustical Engineering degree from the world-renowned
ISVR in Southampton UK, the call of programming brought him back and he
has been working as a Web developer ever since. He uses both Linux and
Windows platforms. He still lives in the UK, and is currently living
happily with his wife.
Copyright © 2006, Pete Savage. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
HelpDex
By Shane Collinge
These images are scaled down to minimize horizontal scrolling.
Flash problems?
All HelpDex cartoons are at Shane's web site,
www.shanecollinge.com.
Talkback: Discuss this article with The Answer Gang
Part computer programmer, part cartoonist, part Mars Bar. At night, he runs
around in his brightly-coloured underwear fighting criminals. During the
day... well, he just runs around in his brightly-coloured underwear. He
eats when he's hungry and sleeps when he's sleepy.
Copyright © 2006, Shane Collinge. Released under the
Open Publication license
unless otherwise noted in the body of the article. Linux Gazette is not
produced, sponsored, or endorsed by its prior host, SSC, Inc.
Published in Issue 126 of Linux Gazette, May 2006
The Linux Launderette
Contents:
 ./configure humour
./configure humour
- Stupidity
- Debian changes its position on the GFDL
- Delaveaux
- Weather
- Interesting mail on the wine-devel list
 ./configure humour
./configure humour
Mon, 13 Mar 2006
From Thomas Adam
The link below was posted into #fvwm by a German speaking person -- my
German is like my Russian in that respect: non-existant. Nevertheless
I picked out through the bits I understood -- quite amusing.
 If
anyone knows of some others, let us all know.
If
anyone knows of some others, let us all know.
http://www.linuxforen.de/forums/showthread.php?t=48669&highlight=linux+liebe
Stupidity
Wed, 26 Apr 2006
From Jimmy O'Regan
Not even off-topic to this list, but this follows on to, and outdoes,
the stupidity I mentioned here:
http://linuxgazette.net/124/misc/nottag/dhs.html#trains
See attached stupidity.html
Debian changes its position on the GFDL
Tue, 14 Mar 2006
From Jimmy O'Regan
http://trends.newsforge.com/article.pl?sid=06/03/13/1615216&from=rss
They still reject anything that has Invariant Sections, but that's only
to be expected.
Delaveaux
Mon, 17 Apr 2006
From Marcin Niewalda
Witam [ Translation below ]
 [Jimmy]
Witamy
[Jimmy]
Witamy
Myślę, że to pomyłka: pan napisał do listy adresowego magazynu
internetu.
[Jimmy]
magazynu internetowego
[Jimmy]
Dlatego, że nasz magazyn jest napisany w angielskim,
[Jimmy]
napisany po angielsku
[Jimmy]
przetłumaczyłem e-mail Pana. Adres, kt�rego Pan szukał, jest
Delaveaux@heagmedianet.de ale myślę, że ten pan mowi tylko po
angielsku i po niemiecku; a nie wiem, czy ten adres jest nadal
aktualny.
[Jimmy]
Forgot to translate what I was writing: I think there has been a
mistake: you have written to the mailing list of an internet magazine.
As our magazine is written in English, I have translated your e-mail.
The address you were looking for is [...], but I think that person only
speaks English and German, and I don't know if that address is still
current.
I'm glad I sprang for the extra thick dictionary
[Ah... see, what happened here is, in issue 64 someone named Roman
Delaveaux sent a 2c tip:
http://linuxgazette.net/issue64/lg_tips64.html]
Poszukuje genealogicznych informacji o rodzine Delaveaux
[Jimmy]
[Searching for genealogical information about the Delaveaux family?]
- Pański mail znalazłem w internecie -
[Jimmy]
[I found sir's mail on the internet]
[Jimmy]
Hmm. There was probably a typo in the first sentence, which would make
the above "While searching for genealogical information about the
Delaveaux family, I found your e-mail address on the internet".
czy byłby Pan zainteresowaniem kontaktem ze mną w tej sprawie?.
[Jimmy]
[Would sir be interested in contacting me about this matter?]
Nadmieniam że dostałem właśnie informację o niszczejącym grobowcu żony Augusta Delaveaux w Osobnicy.
[Jimmy]
[In addition, I have just received information about the spoiling of
the tomb of the wife August Delaveaux in particular.]
[Jimmy]
of the wife of. It's not every day I get to make errors in two languages
in one e-mail
I liked seeing that, as I had been wondering how to 'stack' things in
the genitive case, and have only tried to use it once[1]: Beata had told
me that her brother's fianc�e was visiting, so I said "Musisz pokazywać
narzeczoni twojego brata wszystko warto zobaczyć w Thurles'ie, n.p.
dworzec kolejowy, ulica do Dublina..." (You must show your brother's
fianc�e everything worth seeing in Thurles, e.g. the train station, the
road to Dublin...)
[1] And it wasn't even the genitive, it was the dative, but for feminine
nouns, the dative is the same as the locative, which (aside from a set
of exceptions, of course) is the same as the genitive.
And that's one of the easier aspects of Polish grammar :/
Marcin Niewalda
ps. moja praprababcia była z domu De Laveaux
[Jimmy]
[ps. My great-great-grandmother was De Leveaux]
ps2. drzewo rodziny Delaveaux przygotowane przeze mnie znajduje się pod adresem http://www.genealogia.okiem.pl/laveaux.htm
[Jimmy]
[A Delaveaux family tree prepared by me can be found at this address]
Weather
Wed, 19 Apr 2006
From vince werber
Ok... here I go...
The weather IS changing... Why?... the Sun is getting hotter and the sun
being a 'star' normally gets hotter as it burns out... Basic physics...
Therefore... global warming is real but we have little to do with it...
[Ben]
Not Linux, but - destroying the ozone layer, which blocks a large
percentage of the damaging UV from the Sun, permits those wavelengths to
penetrate our atmosphere. More energy coupled into the system = greater
heat. Basic physics, and we have lots and lots to do with it.
Also, that little star we're discussing is about 5 billion years old,
and is projected to live to a ripe old 10 billion. Claiming that the
weather change over the past couple of years is relevant to the age of
the Sun doesn't make a whole lot of sense.
Depressing aren't I??? (I hope anyway...)
[Ben]
[grin] Nope. Too many optimists here.
I have often said there are two kinds of mystics, the optimystics and
the pessimystics. Now, pessimystics seem to be more in touch with
"reality," but optimystics are happier and live longer for some reason.
The pessimystics have been crying, "The sky is falling, the sky is
falling!" The optimystics say, "No. It just looks that way because we
are ascending."
-- Swami Beyondananda (Steve Bhaerman)
As for 'the great lizzards'... (Dinosaurs)
[Ben]
Are they related to the Great Wizzard?
The stories of my people (Cherokee) claim that we moved south about 15,000
years ago because of an 'ice-age'... such was the ways of 'Turtle
Island' (North America) in those times...
[Ben]
[blink] The Cherokees claim to have records going back that far? That
would be a fascinating new discovery, given that, in general, the reach
of recorded (in the roughest sense) human history is considered to be
~13,000 years, at which point (as far as I know) we had not yet spread
to the Americas. Africa, however, is indeed supposed to have experienced
an "aridity event" lasting from 20,000 to 11,000BC (cooler, drier
climate with less rainforest and greater desert spread.)
As for G-d... read and understand what Einstein was saying... Do you think
the newly formed Nation of Israel would have even considered a 'non-believer'
as their first leader?
[Ben]
Um, yeah, actually. Israel was never a theocracy - and Einstein had
clearly, repeatedly, and publicly stated his absence of belief in a
"personal God".
http://www.infidels.org/library/historical/albert_einstein
[Ben]
Modern Israel, I should have said. Not that anyone from a couple of
thousand years ago was asking Einstein anything, but still worth
clarifying.
[Rick]
In fact, the founding fathers of that state in 1948 were overwhelmingly
secular people (which is still true of its citizenry to this day), to
the point where one of the few religious attendees, Moshe Shapira, tried
and failed to get a reference to God into the Declaration of
Independence draft, which was vetoed by the majority Labour Party
attendees.
Eventually, as a sop to make everyone happy, the concluding sentence was
amended to read "With trust in the rock of Israel ["tzur Yisrael" in the
original Hebrew text]...."
Shapira was thus free to interpret it as a reference to "the Rock of
Israel" (i.e., God), while nearly everyone else could read it as a
poetic reference to the territory in question, and historical roots.
Why do I use Slackware? To avoid all of the above and all of those Microsoft
'undocumented features' (bugs)... <heh>
Have a good day and a better tomorrow!
BTW
Theory's are just that... theory's... based in air... not provable... Keep the
'truth' and pass me the 'facts'...
[Ben]
Erm... I think you've confused the popular and the actual meanings of
"theory", Vince. As used by scientists, it means "a well-substantiated
explanation of some aspect of the natural world", not "wild guess".
However, scientists - in contrast to priests - are willing to learn new
and better explanations for natural phenomena, and thus change their
theories. This is what intelligent human beings do; this is how our
state of knowledge continues to improve.
Interesting mail on the wine-devel list
Mon, 13 Mar 2006
From Jimmy O'Regan
http://www.winehq.org/pipermail/wine-devel/2006-March/045546.html
In short, a Microsoft employee mailed a Wine developer asking for help
with a function (presumably under the assumption that the Wine developer
had written MS's version). Normally, that'd be enough to make me start
watching the skies for signs of porcine bombing raids, but the reason
the MS guy wrote was to not recommend a customer upgrade to the latest
version of Windows!
Talkback: Discuss this article with The Answer Gang
Published in Issue 126 of Linux Gazette, May 2006
