| [ << ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |
In this chapter, we describe the principles of the gnugo DFA
pattern matcher. The aim of this system is to permit a fast
pattern matching when it becomes time critical like in owl
module (12.1 The Owl Code). Since GNU Go 3.2, this is enabled
by default. You can still get back the traditional pattern matcher
by running configure --disable-dfa and then recompiling
GNU Go.
Otherwise, a finite state machine called a Deterministic Finite State Automaton (10.2 What is a DFA) will be built off line from the pattern database. This is used at runtime to speedup pattern matching (10.3 Pattern matching with DFA and 10.5 Incremental Algorithm). The runtime speedup is at the cost of an increase in memory use and compile time.
10.1 Introduction to the DFA Scanning the board along a path 10.2 What is a DFA A recall of language theory. 10.3 Pattern matching with DFA How to retrieve go patterns with a dfa ? 10.4 Building the DFA Playing with explosives. 10.5 Incremental Algorithm The joy of determinism. 10.6 Some DFA Optimizations Some possible optimizations.
The general idea is as follows:
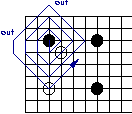
For each intersection of the board, its neighbourhood is scanned following a predefined path. The actual path used does not matter very much; GNU Go uses a spiral as shown below.
In each step of the path, the pattern matcher jumps into a state determined by what it has found on the board so far. If we have successfully matched one or several patterns in this step, this state immediately tells us so (in its attribute). But the state also implicitly encodes which further patterns can still get matched: The information stored in the state contains in which state to jump next, depending on whether we find a black, white or empty intersection (or an intersection out of board) in the next step of the path. The state will also immediately tell us if we cannot find any further pattern (by telling us to jump into the error state).
These sloppy explanations may become clearer with the definitions in the next section (10.2 What is a DFA).
Reading the board following a predefined path reduces the two dimentional pattern matching to a linear text searching problem. For example, this pattern
?X? .O? ?OO |
scanned following the path
B C4A 5139 628 7 |
gives the string "OO?X.?*O*?*?" where "?" means 'don't care' and "*" means 'don't care, can even be out of board'.
So we can forget that we are dealing with two dimensional patterns and consider linear patterns.
The acronym DFA means Deterministic Finite state Automaton (See http://www.eti.pg.gda.pl/~jandac/thesis/node12.html or Hopcroft & Ullman "Introduction to Language Theory" for more details). DFA are common tools in compilers design (Read Aho, Ravi Sethi, Ullman "COMPILERS: Principles, Techniques and Tools" for a complete introduction), a lot of powerfull text searching algorithm like Knuth-Morris-Pratt or Boyer-Moore algorithms are based on DFA's (See http://www-igm.univ-mlv.fr/~lecroq/string/ for a bibliography of pattern matching algorithms).
Basically, a DFA is a set of states connected by labeled transitions. The labels are the values read on the board, in gnugo these values are EMPTY, WHITE, BLACK or OUT_BOARD, denoted respectively by '.','O','X' and '#'.
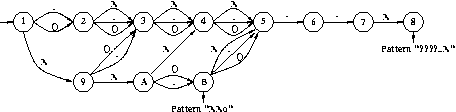
The best way to represent a dfa is to draw its transition graph: the pattern "????..X" is recognized by the following DFA:

This means that starting from state [1], if you read '.','X' or 'O' on the board, go to state [2] and so on until you reach state [5]. From state [5], if you read '.', go to state [6] otherwise go to error state [0]. And so on until you reach state [8]. As soon as you reach state [8], you recognize Pattern "????..X"
Adding a pattern like "XXo" ('o' is a wildcard for not 'X') will transform directly the automaton by synchronization product (10.4 Building the DFA). Consider the following DFA:
By adding a special error state and completing each state by a transition to error state when there is none, we transform easily a DFA in a Complete Deterministic Finite state Automaton (CDFA). The synchronization product (10.4 Building the DFA) is only possible on CDFA's.
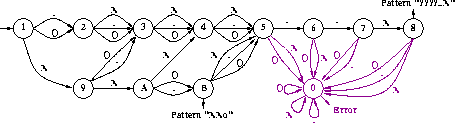
The graph of a CDFA is coded by an array of states: The 0 state is the "error" state and the start state is 1.
----------------------------------------------------
state | . | O | X | # | att
----------------------------------------------------
1 | 2 | 2 | 9 | 0 |
2 | 3 | 3 | 3 | 0 |
3 | 4 | 4 | 4 | 0 |
5 | 6 | 0 | 0 | 0 |
6 | 7 | 0 | 0 | 0 |
7 | 0 | 0 | 8 | 0 |
8 | 0 | 0 | 0 | 0 | Found pattern "????..X"
9 | 3 | 3 | A | 0 |
A | B | B | 4 | 0 |
B | 5 | 5 | 5 | 0 | Found pattern "XXo"
----------------------------------------------------
|
To each state we associate an often empty list of attributes which is the list of pattern indexes recognized when this state is reached. In '`dfa.h'' this is basically represented by two stuctures:
|
Recognizing with a DFA is very simple
and thus very fast
(See 'scan_for_pattern()' in the '`engine/matchpat.c'' file).
Starting from the start state, we only need to read the board following the spiral path, jump from states to states following the transitions labelled by the values read on the board and collect the patterns indexes on the way. If we reach the error state (zero), it means that no more patterns will be matched. The worst case complexity of this algorithm is o(m) where m is the size of the biggest pattern.
Here is an example of scan:
First we build a minimal dfa recognizing these patterns: "X..X", "X???", "X.OX" and "X?oX". Note that wildcards like '?','o', or 'x' give multiple out-transitions.
----------------------------------------------------
state | . | O | X | # | att
----------------------------------------------------
1 | 0 | 0 | 2 | 0 |
2 | 3 | 10 | 10 | 0 |
3 | 4 | 7 | 9 | 0 |
4 | 5 | 5 | 6 | 0 |
5 | 0 | 0 | 0 | 0 | 2
6 | 0 | 0 | 0 | 0 | 4 2 1
7 | 5 | 5 | 8 | 0 |
8 | 0 | 0 | 0 | 0 | 4 2 3
9 | 5 | 5 | 5 | 0 |
10 | 11 | 11 | 9 | 0 |
11 | 5 | 5 | 12 | 0 |
12 | 0 | 0 | 0 | 0 | 4 2
----------------------------------------------------
|
We perform the scan of the string "X..XXO...." starting from state 1:
Current state: 1, substring to scan : X..XXO....
We read an 'X' value, so from state 1 we must go to state 2.
Current state: 2, substring to scan : ..XXO....
We read a '.' value, so from state 2 we must go to state 3 and so on ...
Current state: 3, substring to scan : .XXO.... Current state: 4, substring to scan : XXO.... Current state: 6, substring to scan : XO.... Found pattern 4 Found pattern 2 Found pattern 1 |
After reaching state 6 where we match patterns 1,2 and 4, there is no out-transitions so we stop the matching. To keep the same match order as in the standard algorithm, the patterns indexes are collected in an array and sorted by indexes.
The most flavouring point is the building of the minimal DFA recognizing a given set of patterns. To perform the insertion of a new pattern into an already existing DFA one must completly rebuild the DFA: the principle is to build the minimal CDFA recognizing the new pattern to replace the original CDFA with its synchronised product by the new one.
We first give a formal definition: Let L be the left CDFA and R be the right one. Let B be the synchronised product of L by R. Its states are the couples (l,r) where l is a state of L and r is a state of R. The state (0,0) is the error state of B and the state (1,1) is its initial state. To each couple (l,r) we associate the union of patterns recognized in both l and r. The transitions set of B is the set of transitions (l1,r1)---a--->(l2,r2) for each symbol 'a' such that both l1--a--->l2 in L and r1--a--->r2 in R.
The maximal number of states of B is the product of the number of states of L and R but almost all this states are non reachable from the initial state (1,1).
The algorithm used in function 'sync_product()' builds
the minimal product DFA only by keeping the reachable states.
It recursively scans the product CDFA by following simultaneously
the transitions of L and R. A hast table
(gtest) is used to check if a state (l,r) has
already been reached, the reachable states are remapped on
a new DFA. The CDFA thus obtained is minimal and recognizes the
union of the two patterns sets.
For example these two CDFA's:
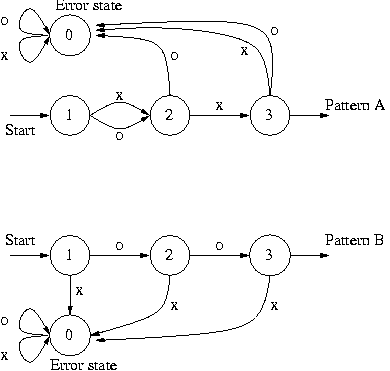
Give by synchronization product the following one:
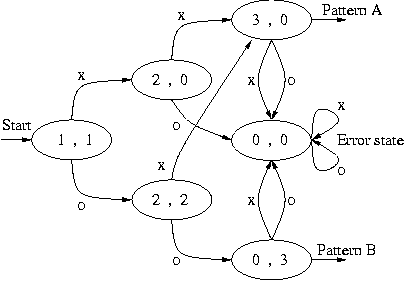
It is possible to construct a special pattern database that generates an "explosive" automaton: the size of the DFA is in the worst case exponential in the number of patterns it recognizes. But it doesn't occur in pratical situations: the dfa size tends to be stable. By stable we mean that if we add a pattern which greatly increases the size of the dfa it also increases the chance that the next added pattern does not increase its size at all. Nevertheless there are many ways to reduce the size of the DFA. Good compression methods are explained in Aho, Ravi Sethi, Ullman "COMPILERS: Principles, Techniques and Tools" chapter Optimization of DFA-based pattern matchers.
The incremental version of the DFA pattern matcher is not yet implemented in gnugo but we explain here how it will work. By definition of a deterministic automaton, scanning the same string will reach the same states every time.
Each reached state during pattern matching is stored in a stack
top_stack[i][j] and state_stack[i][j][stack_idx]
We use one stack by intersection (i,j). A precomputed reverse
path list allows to know for each couple of board intersections
(x,y) its position reverse(x,y) in the spiral scan path
starting from (0,0).
When a new stone is put on the board at (lx,ly), the only work
of the pattern matcher is:
|
In most situations reverse(lx-i,ly-j) will be inferior to top_stack[i][j]. This should speedup a lot pattern matching.
The dfa is constructed to minimize jumps in memory making some assumptions about the frequencies of the values: the EMPTY value is supposed to appear often on the board, so the the '.' transition are almost always successors in memory. The OUT_BOARD are supposed to be rare, so '#' transitions will almost always imply a big jump.
| [ << ] | [ >> ] | [Top] | [Contents] | [Index] | [ ? ] |