suivant: FAQ monter: Documentation générale Sched précédent: Script Table des matières
Vous devez choisir (via pwgen par exemple) un password de connexion au sched_master. Celui ci n'est pas utilisé par un humain. Il peut donc faire 50 caractères de long.
La configuration suivante est un exemple qui utilise un seul noeud. Les job seront identifiés sur la machine plume. Le module slave sera identifié sous le nom de plume2.
La base de donnée sched doit être accessible. La structure doit être remplie et vous devez connaître la chaîne de connexion (dsn). (Cf 2.5)
Les cgi sched_view doivent être accessibles via votre navigateur. (Cf 2.6.2).
Le sched_job et le sched_slave utilisent un espace de travail (work_dir) pour stocker les fichiers de traces. Ce répertoire doit être accessible à vos utilisateurs sched (lançant les job et le slave).
Pour gérer les déconnexions, les composants sched utilisent un espace de stockage interne (db_dir). Il en faut un par composant. Seul le composant a donc besoin d'y écrire des données.
mkdir -p /tmp/sched/wd mkdir -p /tmp/sched/master/db mkdir -p /tmp/sched/slave/db mkdir -p /tmp/sched/job/db
localhost:~/ cat /etc/sched/master.cfg [main] logfile=/tmp/master.log debug=5 [master] job_dir=/tmp/sched/job db_dir=/tmp/sched/master/db dsn=dbname=sched;user=sched;password=xxx group=sched user=nobody master_port=5544 view_passwd=motdepass view_ip=127.0.0.1
localhost:~/ cat /etc/sched/cgi.cfg [main] logfile=/tmp/cgi.log debug=0 [cgi] master_ip=localhost master_port=5544 master_passwd=motdepass master_retry=10 dsn=dbname=sched;user=sched;password=xxx xfer_port=8081
localhost:~/ cat /etc/sched/slave.cfg [main] logfile=/tmp/slave.log debug=5 [xfer] xfer_inet = 0.0.0.0 xfer_port = 8081 xfer_user = nobody xfer_group = nogroup [slave] master_ip=localhost master_port=5544 master_passwd=mdpplume2 master_retry=10 work_dir=/tmp/sched/wd db_dir=/tmp/sched/slave/db hostname=plume2
localhost:~/ cat /etc/sched/job.cfg [main] logfile=/tmp/job.log debug=5 [job] work_dir=/tmp/sched/wd job_dir=/tmp/sched/job master_ip=localhost master_port=5544 master_passwd=mdpplume master_ping=30 db_dir=/tmp/sched/job/db hostname=plume
Le cgi http://localhost/cgi-bin/sched/sched_list_host.cgi permet d'ajouter les deux machines du tutorial.
L'utilisation de sched_builder permet de construire un job graphiquement. (voir la démo http://localhost/sched/doc/tutorial1.swf)
En ligne de commande, l'utilitaire sched_job_validate permet de valider un job.
localhost:~# sched_job_validate -j jobname.xml [24/10/2004 15:15:49] <5> Sched::init: I : Demarrage I : verification ok
Aller sur http://localhost/cgi-bin/sched/sched_commit_job.cgi et uploader le fichier job.
En ligne de commande, l'utilitaire sched_job_commit permet de valider un job et de le mettre en production.
localhost:~# sched_job_commit -j jobname.xml \
-r 'version 1 - test avant mise en prod'
[24/10/2004 15:15:49] <5> Sched::init: I : Demarrage
I : verification ok
I : OK 19 is registred
Si le job n'est pas syntaxiquement correcte, il ne sera pas inscrit dans la base sched.
Une fois le job enregistré dans la base, il peut être utilisé en mode réseau. Le mode réseau permet d'avoir un historique centralisé de l'exécution des job et de pouvoir exécuter des taches sur différentes machines. Dans cette version, le déploiement d'un job est manuel, il faut copier le fichier job (au bit près) sur le serveur cible dans le répertoire job_dir. Le serveur cible doit être autorisé à exécuter le job (champ host dans le descriptif du job).
Une fois le job en place sur le serveur cible, l'option -dry-run de sched_job permet de faire une simulation du job. Toutes les commandes seront remplacées au dernier moment juste avant l'éxécution par un sleep 1.
Cela permet de valider les machines utilisées, les chemins des fichiers entrée/sortie, des utilisateurs utilisés etc..
localhost:~# sched_job -j job.xml --dry-run
Le programme sched_job permet d'exécuter un job. Le job se connecte sur le sched_master et exécute toutes les tâches enregistrées.
Le compte utilisateur qui execute le job doit pouvoir lire le fichier de configuration job.cfg (cf 3.4).
localhost:~# sched_job -j job.xml
Sur un système unix via cron
0 5 * * sched_job -j job.xml > /dev/null 2>&1
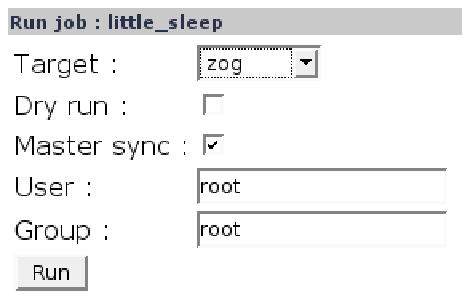
L'interface d'administration sched_view permet de lancer des job sur les machines connectées. (cf fig 10 et 11)
La version d'un job est obtenu en fonction de son checksum md5. Il est donc pas possible de modifier un job une fois mis en production.
Eric 2005-12-17
![\includegraphics[width=13cm]{inc/sched_view_run.eps}](img10.png)